
Blog
All the latest info and insights from the Akka team
Featured
Agentic AI: Why Experience Matters More Than Hype
Experience matters more than hype. Why most agentic projects fail—and what 15 years of production-hardened experience reveals about building them right.

News: Akka and Deloitte Canada Collaborate to Deliver Agentic AI at Scale
Akka and Deloitte join forces to solve critical enterprise agentic AI issues, including cost, performance, and resilience.
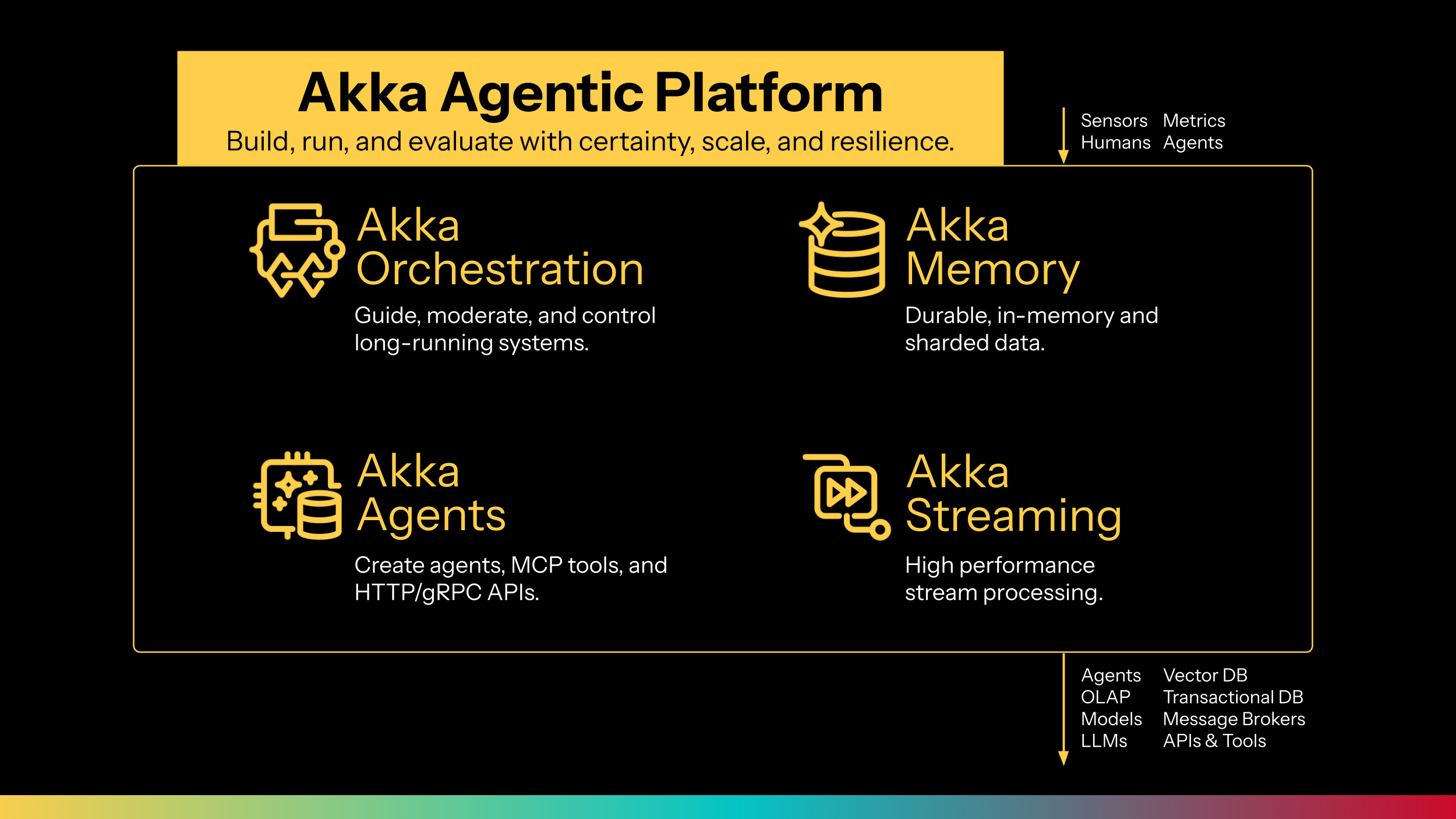
Announcing the Akka Agentic Platform
Introducing Akka Orchestration, Akka Agents, Akka Memory, and Akka Streaming; integrated offerings that deliver 3x the velocity, 1/3rd the compute and any SLA for every agentic system.



















