Overview
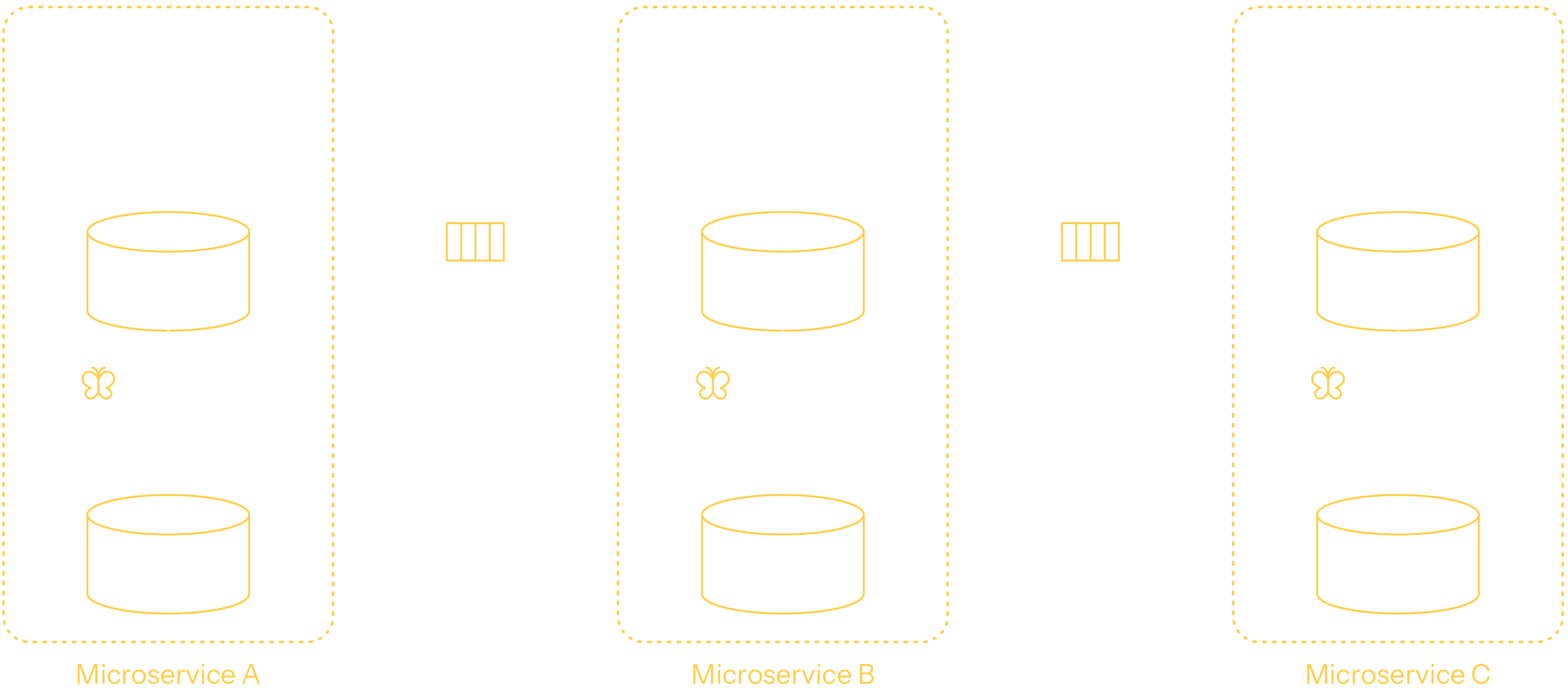
Transactional apps, sometimes called CRUD apps, are business processes requiring operational, real-time data access. These applications embody critical business functions by performing create, read, update, or delete operations on persistent data with transactionally-safe properties: atomicity, consistency, isolation, and durability (ACID). While transactional apps can be straightforward for small-scale operations, they face significant challenges in maintaining data accuracy and reliability in high-volume, multi-user environments.