Built for agentic workloads
Long-lived processes
Long-lived processes like multi-step agents, background jobs, and business workflows require durable execution. Akka persists their state through snapshots and change events, allowing processes to pause, resume, or recover without losing context. These agents can run for seconds, hours, or days without being tied to a single machine.
Transactional
Transactional processes are short-lived and reactive, such as handling user actions, responding to external events, or processing commands. Akka actors provide lightweight, isolated execution units that maintain their own state, enabling fast, parallel, and elastic processing without shared bottlenecks.
Continuous
Continuous processes like audio/video streams, telemetry ingestion, and real-time sensor data require high-throughput, low-latency pipelines. Akka Streams support bounded and unbounded data flows with built-in flow control and error handling, making it ideal for processing dynamic, continuous input.
Data and logic together
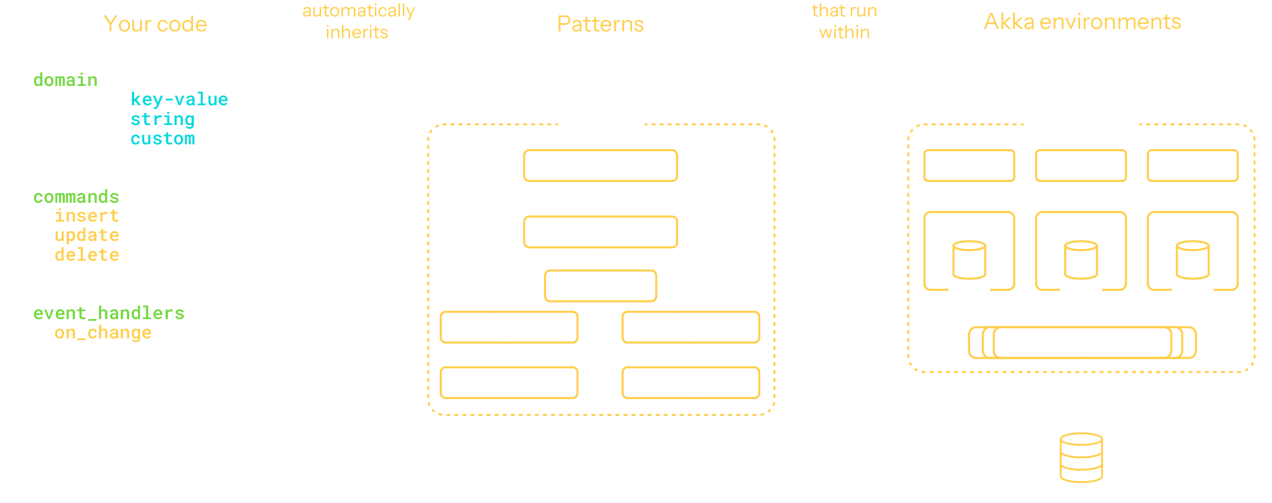
Traditional systems separate application logic from data storage, leading to coordination overhead, latency, and fragility. Akka takes a different approach: each actor encapsulates its own state and logic. This means the application itself becomes the system of record.
Event-driven fabric
Asynchronous messaging
Akka components communicate through lightweight, non-blocking messages, decoupling producers from consumers. This model not only improves responsiveness and resource efficiency. Components don’t wait, they react when events arrive, allowing the system to remain responsive under load and elastic as demand fluctuates.
Event sourcing
Every meaningful change in Akka is captured as an event, creating a durable, replayable log of system behavior. This event-sourced model ensures a full audit trail, supports temporal debugging, and enables robust recovery by replaying events—optionally from snapshots—to restore exact state and context. The underlying event store is fully managed by Akka and scales elastically with demand, providing built-in durability without added operational overhead.
Distributed coordination
Akka’s event-driven fabric extends beyond internal messaging to handle external systems: APIs, vector databases, tools, and other agents that may be slow, unreliable, or transient. Rather than tightly coupling to these services, Akka agents coordinate with them asynchronously, using event-driven patterns like circuit breakers, retries with backoff, and supervision strategies. This keeps failures isolated and recoverable, while allowing integration logic to remain composable, observable, and fault-tolerant across boundaries.
0 → ∞ → 0
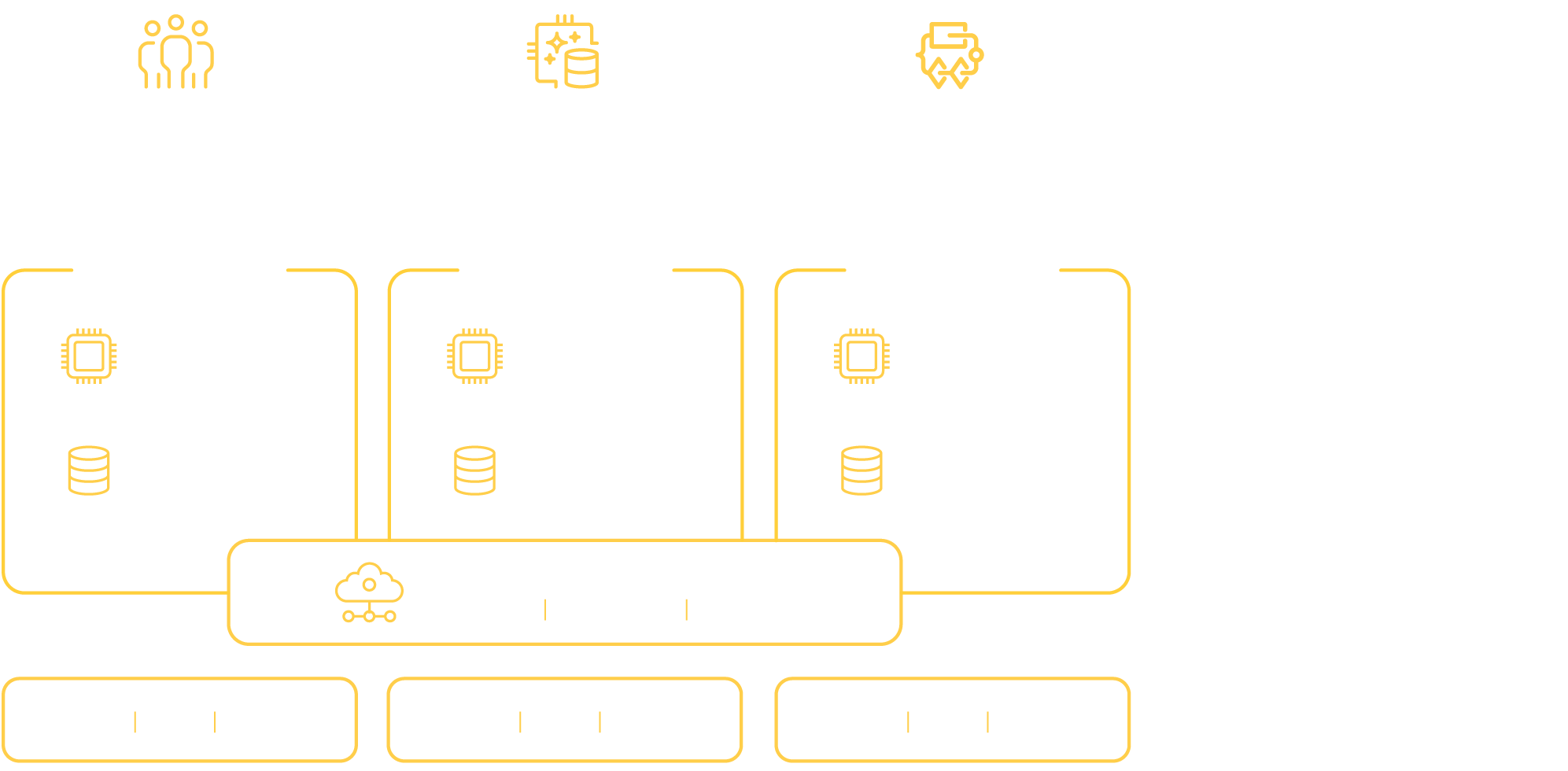
Distributing from within
Akka agents are microservices that embed an Akka runtime that distributes data everywhere it needs to be. Agents scale along four dimensions to ensure elasticity and resilience.
Akka agents shard data and segregate queries while applying dynamic compute separately to each entity and view component type.
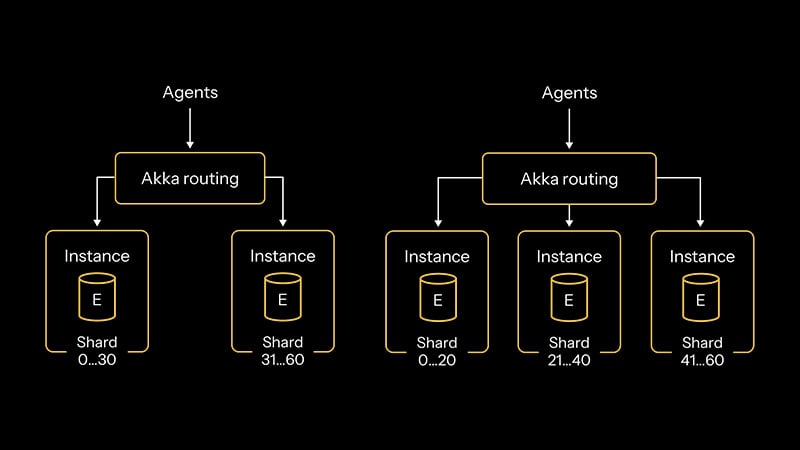
Data sharding
App data is partitioned across in-memory, durable nodes. Akka routes user requests to the correct instance.

Data rebalancing
Data shards are re-balanced as the number of runtime nodes changes.

Query elasticity
Data queries are offloaded to separate compute. Services scale their entity and view components separately.
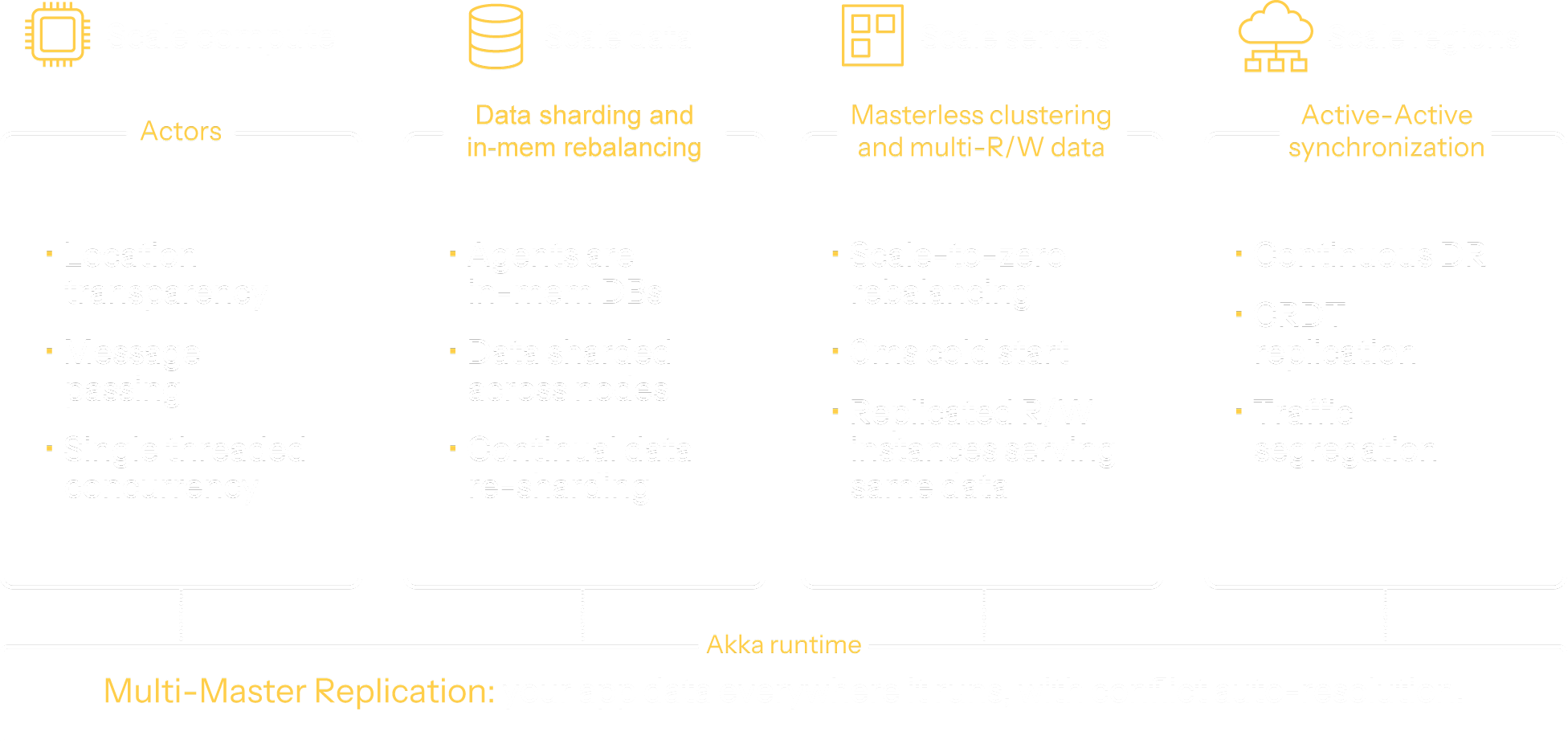
Self-contained agents that recover and relocate
Akka bundles logic and transactional state together, turning each instance into a self-contained, in-memory database. This co-location eliminates coherence risks and allows agents to recover via event sourcing. With built-in location transparency, agents can run close to end users for lower latency and higher responsiveness.
Scale-out writes with live, consistent data
Akka can run multiple read-write instances to increase throughput and efficiency. State is automatically sharded across the cluster, and updates are replicated using eventual consistency and CRDT techniques. This allows concurrent modification of shared state with convergence, much like collaborative editing in Google Docs, but for application data.
Hybrid execution across clouds
Akka forms masterless clusters that self-organize, with built-in split-brain resolution to maintain consistency under network partitions. These clusters can span clouds, regions, or data centers using brokerless, encrypted messaging over gRPC. This enables secure, low-latency execution wherever agents are needed, without relying on a central coordinator.

Self healing
Akka apps can auto-recover by persisting state changes. Your app’s state changes are captured as replayable, sequential snapshots and events. The event store is Akka-managed infrastructure that grows and shrinks as needed.
Embedded expertise
Responsive by Design means we build with the proven design patterns from the Reactive Principles - endorsed by 33,000+ experts that signed the Reactive Manifesto. And, we bake them into your services and the Akka runtime so you don’t have to learn or implement them.

The backbone of agentic AI, distributed systems, and OSS sustainability
How does Akka clustering work?
