


Akka is the only development framework that provides clustering within offline development, self-managed nodes on any infrastructure, or on the Akka Platform.
Akka services cluster from within, forming their own clusters through discovery and connecting with other Akka nodes. Whether you build a data, API, or agentic AI service—and whether your service is stateful or stateless—that service is inherently clustered. While you can opt to run a single node cluster of Akka, you can just as easily run a multi-node cluster. Clustered services then gain essential capabilities that enable elasticity and resilience: discovery, data sharding, data rebalancing, fan-out/in compute, service-to-service brokerless messaging, conflict-free data replication, split-brain networking resolution, and consensus. A longer explanation of how Akka’s clustering works is included at the end of this document
Akka has been production-hardened for over 15 years. Akka clustering doesn’t require you to install additional infrastructure or a “platform server” because clustering is embedded within your services.
Akka’s clustering and persistence architecture makes it possible to support high throughput with deterministic low latency. Akka’s programming model enables you to focus on the business logic in fine-grained entities that are modeled one-to-one with your business domain.
The core component is the stateful entity. Each entity has an identity, and for each entity identity, there is only one instance that holds the system of record and processes requests for that entity. There can be many millions of entities, which are distributed over many nodes in the cluster to support horizontal scalability. Akka ensures that each entity only exists as one instance in the cluster. This property of an entity has many benefits for high performance and simple programming models.
The state of the entity is kept in memory as long as the entity is active. This means it can serve read requests or command validation before updating, without an additional read from the database. In contrast, a traditional database-centric architecture with a stateless application would require a read-modify-write cycle with optimistic locking to update the record in the database. The additional read before validating and updating is less efficient and adds load to the database, compared to already having the state for validation in memory. Optimistic locking can result in contention and retries that increase the load when the system is already under pressure.
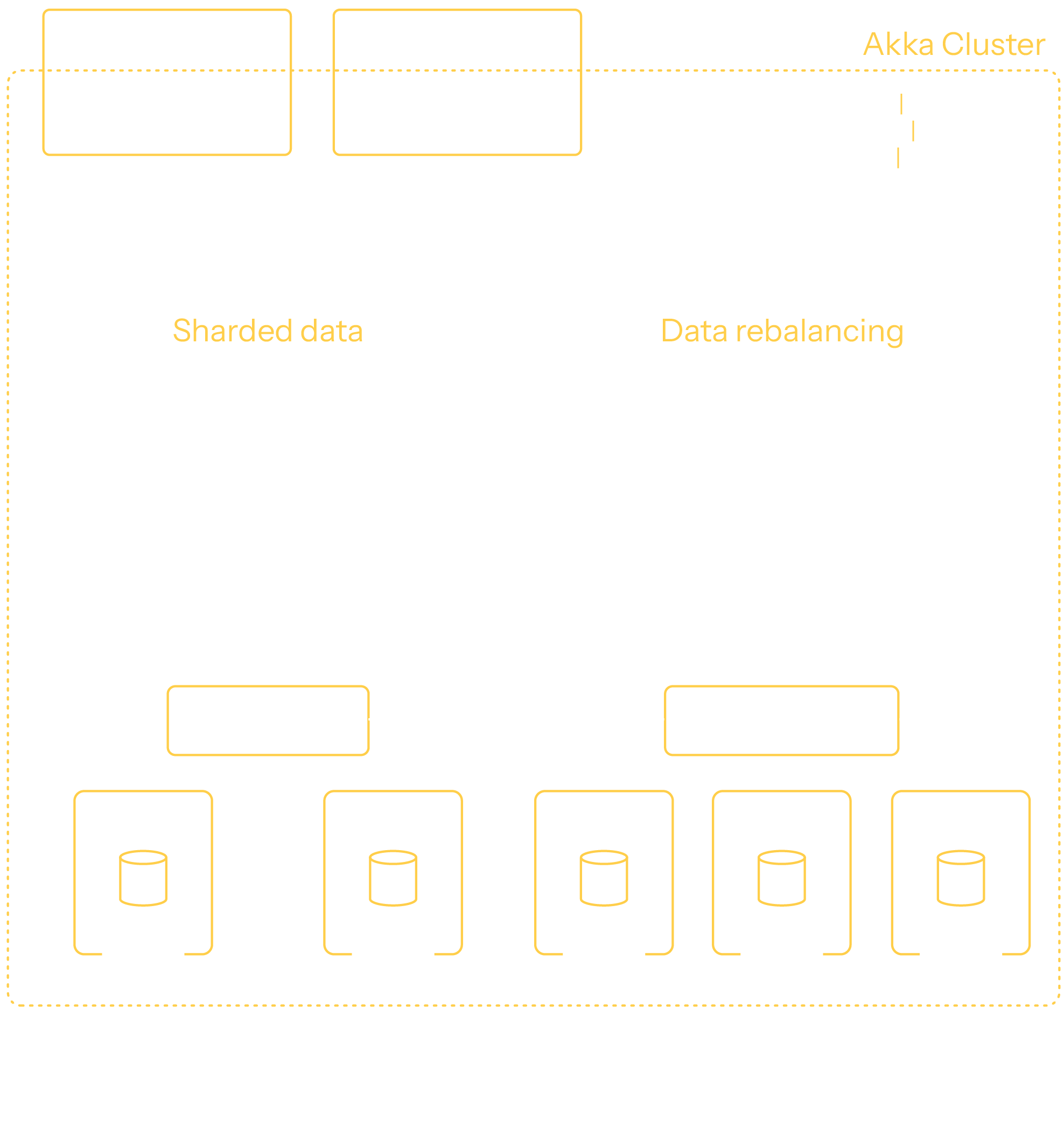
To ensure that the entity instance doesn’t exist in more than one place of the cluster, there must be coordination between the nodes to determine the entity’s location at any given time. Deciding on each individual entity would be too fine-grained; therefore, the entities are grouped into shards. The grouping is based on a deterministic hash function of the entity identifier. For example, you may have 100k entities grouped into 100 shards, spread over 20 nodes—that is,5 shards per node. To increase system capacity, you may scale the cluster to 25 nodes. The shards will be automatically rebalanced so that some shards move to the new nodes, resulting in 4 shards per node.
When a request to an entity arrives at one node, Akka must know where the corresponding shard is located and route the request to that node. Either it already knows the location—because it has handled requests for this shard previously and can use the cached location—or it asks the shard coordinator for the location. The coordinator makes consistent decisions within the cluster about where shards are located and handles the rebalance process for those shards.
There might not be room for all entities to remain active in memory at all times; therefore, entities can be passivated—for example, with the least-recently-used strategy. When the entity is used again, it recovers its state from durable storage and becomes an active entity, with its system of record in memory backed by consistent durable storage. This recovery process is used during rolling updates, rebalancing, and crashes.
For durable storage, the changes to the entity are stored as events in an append-only event log. The recovery process replays these change events to reconstruct the state. As an optimization, snapshots of the state may be stored occasionally to reduce the number of events that must be read and replayed. In that case, the snapshot is loaded, and the events that occurred after the snapshot are replayed.
The event log is used for more things than just recovering the state of the entities. From the stream of events from all entities, the application can store other representations for the purpose of queries or process the events by calling external services. Event processing can be distributed across many event consumers running in the cluster. This is a data partitioning approach, where events are grouped into slices based on a deterministic hash of the entity identifier that emitted the event. Each event consumer takes responsibility for a range of slices, and Akka manages the event consumers in the cluster. The number of event consumers can be changed dynamically. For this distribution of event consumers, coordination—similar to entity sharding—is needed to ensure that a slice of events is processed by only one consumer.
Additionally, the event log is used for communication between different services or replicas of the entities running in other cloud or edge locations.
We said there is only one instance of a specific entity, but with this event-based replication, we can actually have multiple replicas of the entity to support high availability and low latency in a geographically distributed system. The entities can make updates independent of other replicas, in an active-active way. Concurrent updates are resolved at the application level with CRDTs or application logic.
These features are built on top of the foundations of the Akka cluster, such as the cluster membership, failure detection, and split-brain resolver.
References:

Posts by this author
Share this article