


With Akka, applications are built locally and then operated simultaneously across many regions. We describe this behavior as ‘write once, deploy anywhere, replicate everything’.
Akka applications act as their own in-memory, durable database that can support 100s of millions of concurrent users and terabytes of data. Multi-region stateful applications at gigantic user and data scale enables smoother latency, no downtime disaster recovery, no downtime upgrades, and cross-cloud migrations.
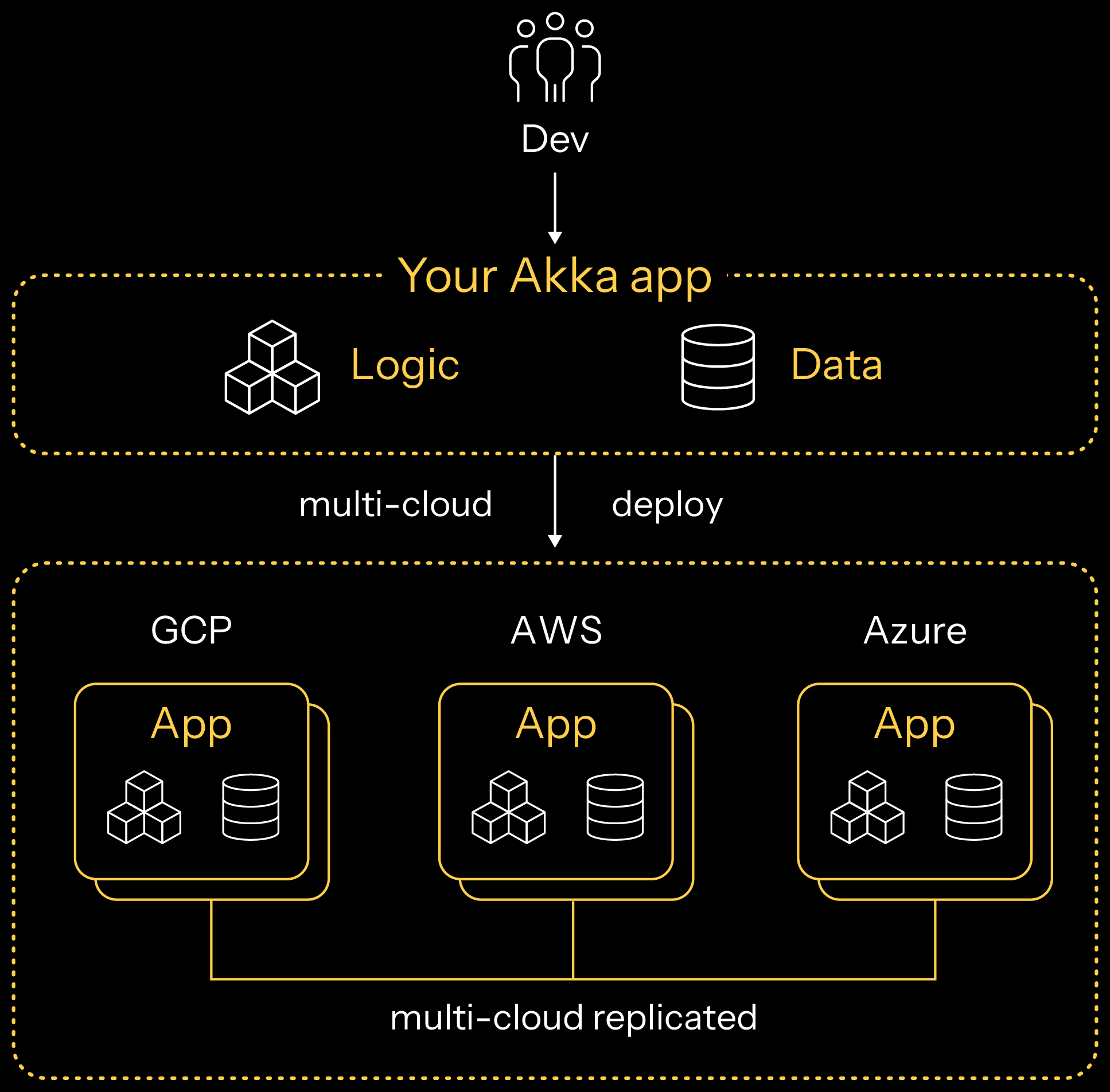
A multi-region application is one where its logic and data are accessible in multiple locations, usually across a WAN where traditional clustering protocols are inefficient.

A region, in this context, is a location where the application has an exposed service endpoint and a unique URL (DNS entry) to access it. Akka enables operators to have their applications operate in three modes:
Multi-region stateful applications that maintain their elasticity and resilience properties are not offered by your database or cloud native infrastructure. How did we do it?
For stateless applications, each application can have many instances in different regions and can reasonably scale out elastically by adding compute and the number of application instances. Within a single region, Akka load balances the incoming request traffic to an available instance. End users to the API of the application take responsibility for determining which region they access and are likely to use a solution like Route53 from AWS.
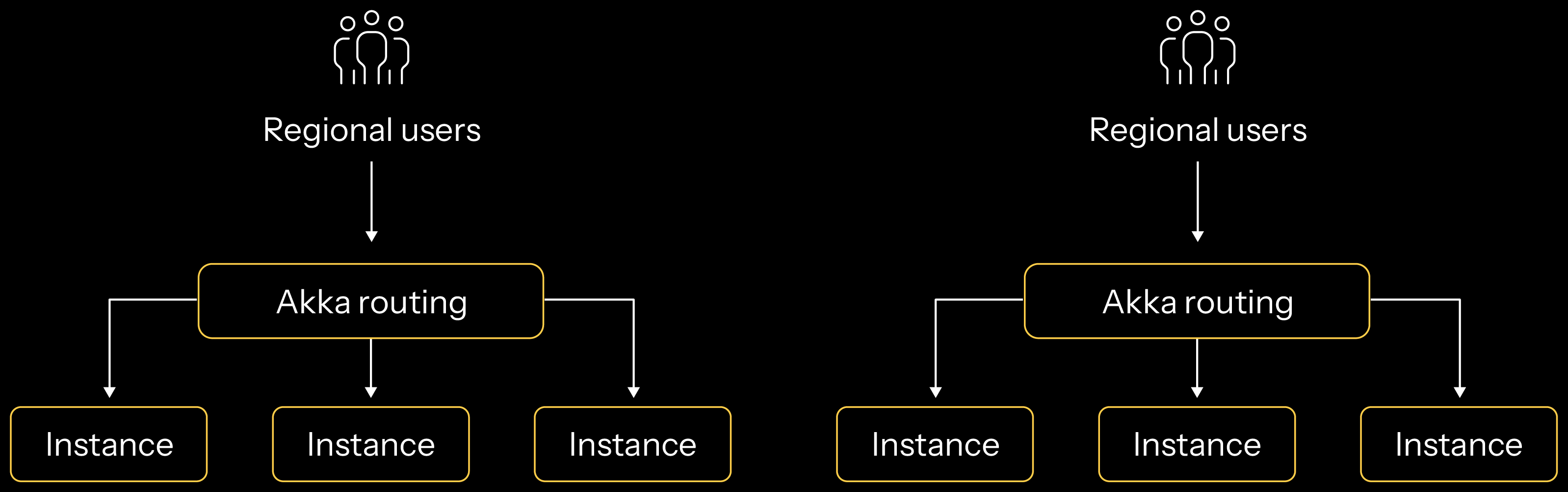
For stateful applications that act as their own in-memory database, those applications must reliably replicate their state changes between regions and then ensure end-user traffic is routed to the correct region and instance that can read or write the data the client specified. There is no shortage of reliability, performance, and durability concerns that must be addressed.
Stateful Akka applications scale horizontally by automating the sharding of the data across a cluster of instances running within a single region. Akka’s infrastructure determines how many instances should exist. Each instance acts as the system of record for the entity it represents, with each instance sharded to represent different slices of data for that type.
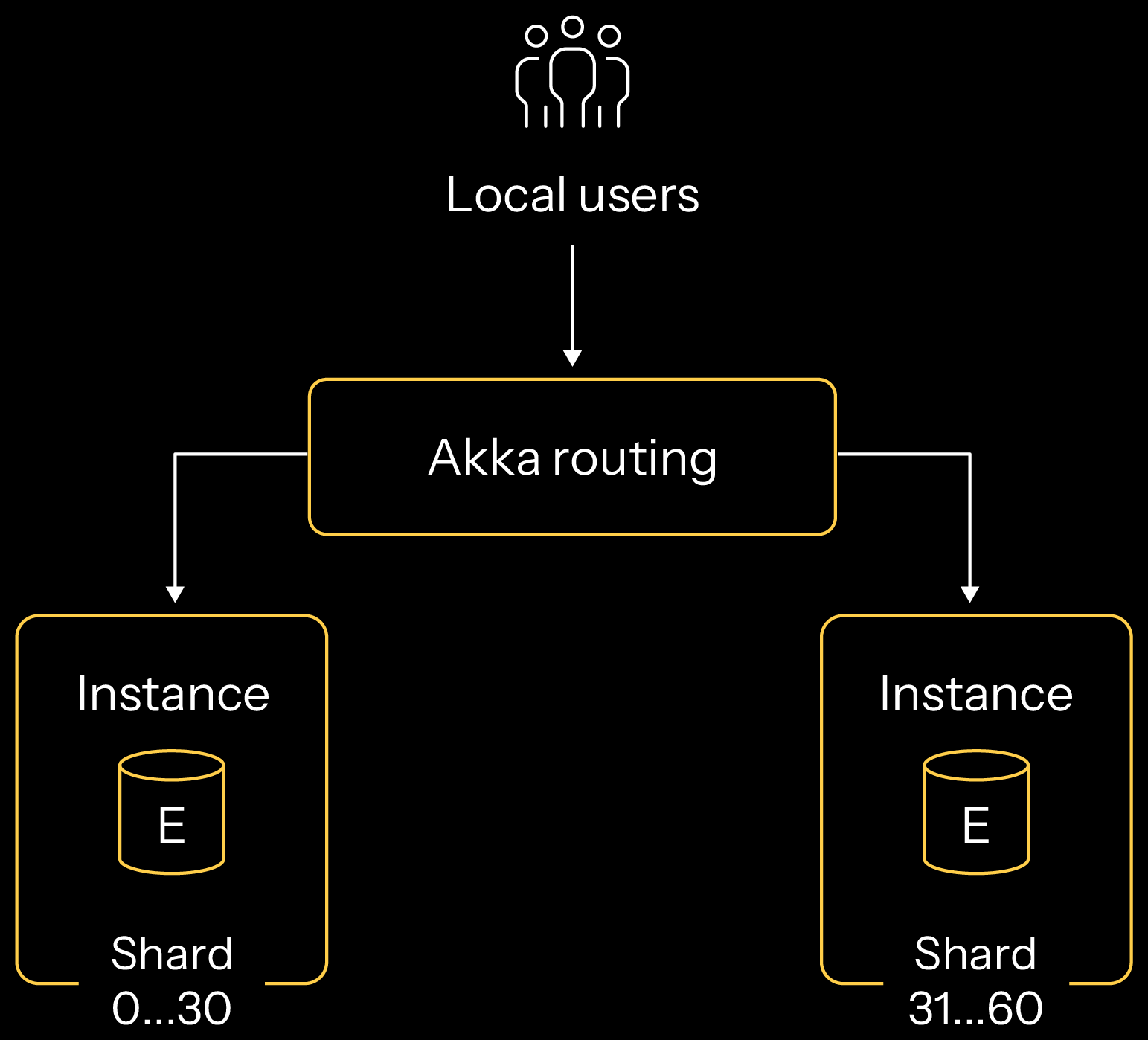
In this example, if an application had 60 unique pieces of data (think of them as 60 unique rows in a database), then Akka would split half of the data into the first instance and the other half of the data in a second instance. The Akka application shards from within, determining which data goes into each location. For performance reasons, it’s usually the case that data remains in the instance it was created within. If the amount of data the application represents is more than the memory allocated to the instances, then the least accessed data is passivated into persistence and reactivated if an end user request for that data is made. Akka also performs routing from within, so as end user traffic requests to read or write to a specific data item, Akka directs the traffic to the instance that houses the right data item.
As demand and traffic increase, Akka increases the compute and memory available to serve the application. As nodes come online, Akka rebalances the shards over the nodes in a cluster. The opposite process occurs as nodes are taken offline as traffic reduces.
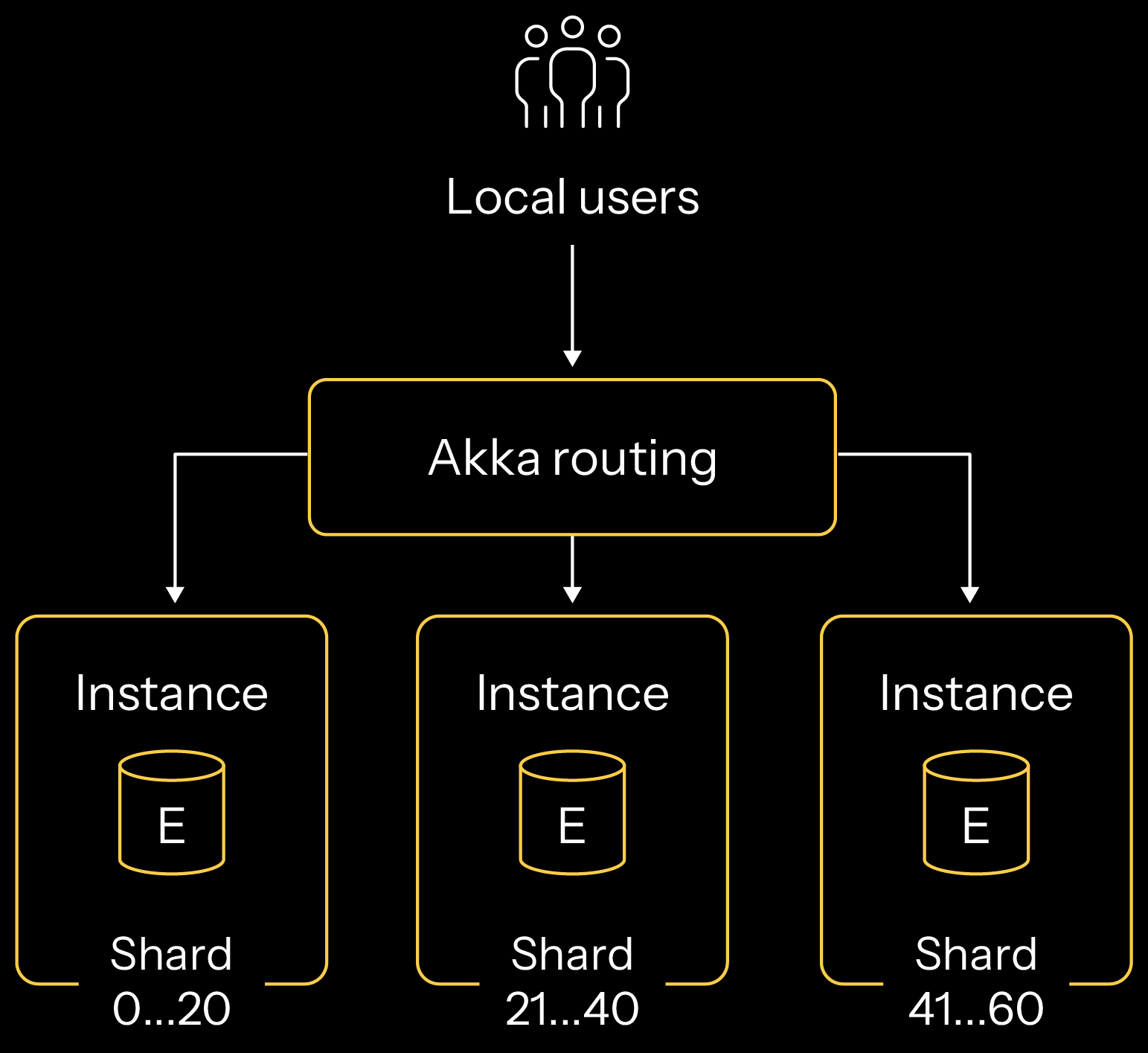
Within a single region, these capabilities are automated through the Akka runtime. The Akka runtime is also enabled from within the application, executing as an embedded kernel compiled into your application’s core to enable your application’s participation in a networked cluster. Akka clustering is, therefore, also enabled from within, allowing stateful applications within your service to discover, join, participate, and leave a cluster. This happens automatically and across a variety of networking boundaries without installing a service mesh or other connectivity backbone. Effectively, each Akka application has its own embedded cluster membership and service mesh backbone operating from within.
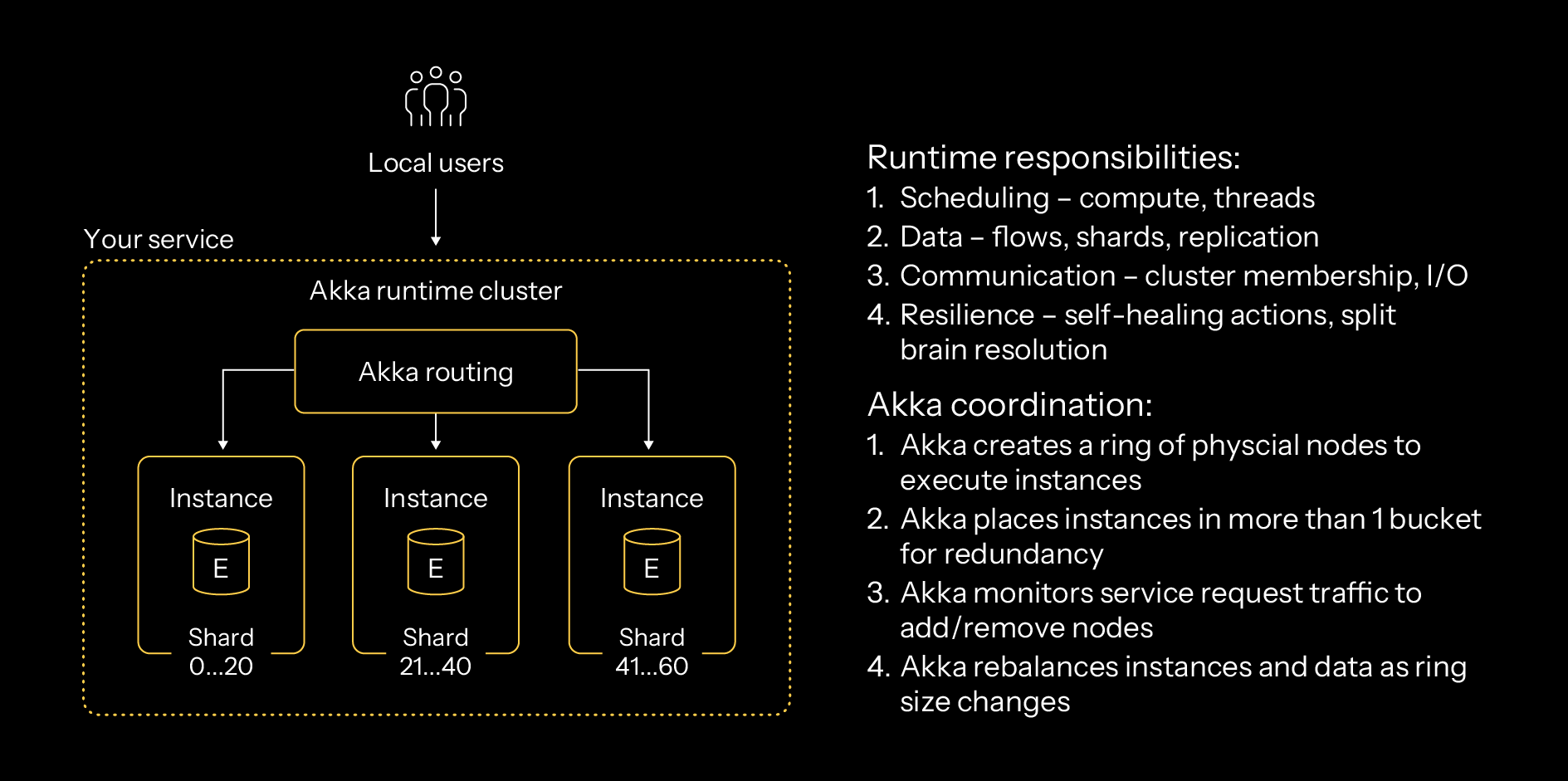
The Akka runtime and its clustering are designed to operate across WAN networks, though in Akka’s operating environments, it’s deployed within a single LAN with cross-LAN communication handled by cross-cluster coordination. Akka creates a ring of nodes to operate your application instances. The data’s location within the cluster is gossiped throughout the cluster and held within more than one member node to offer routing redundancy and failover.
Your application’s state is tracked on a networked (and persisted) event log where each event represents an incremental change to the application’s state. Services with data instances (entities) can be restored from a hardware or network failure by replaying the events of the entities, with the terminating event restoring the entity to its last state. As the event log grows in length and complexity, Akka periodically snapshots the state of an entity which can be used as a starting point to replay events more rapidly than replaying all events from their origination date.
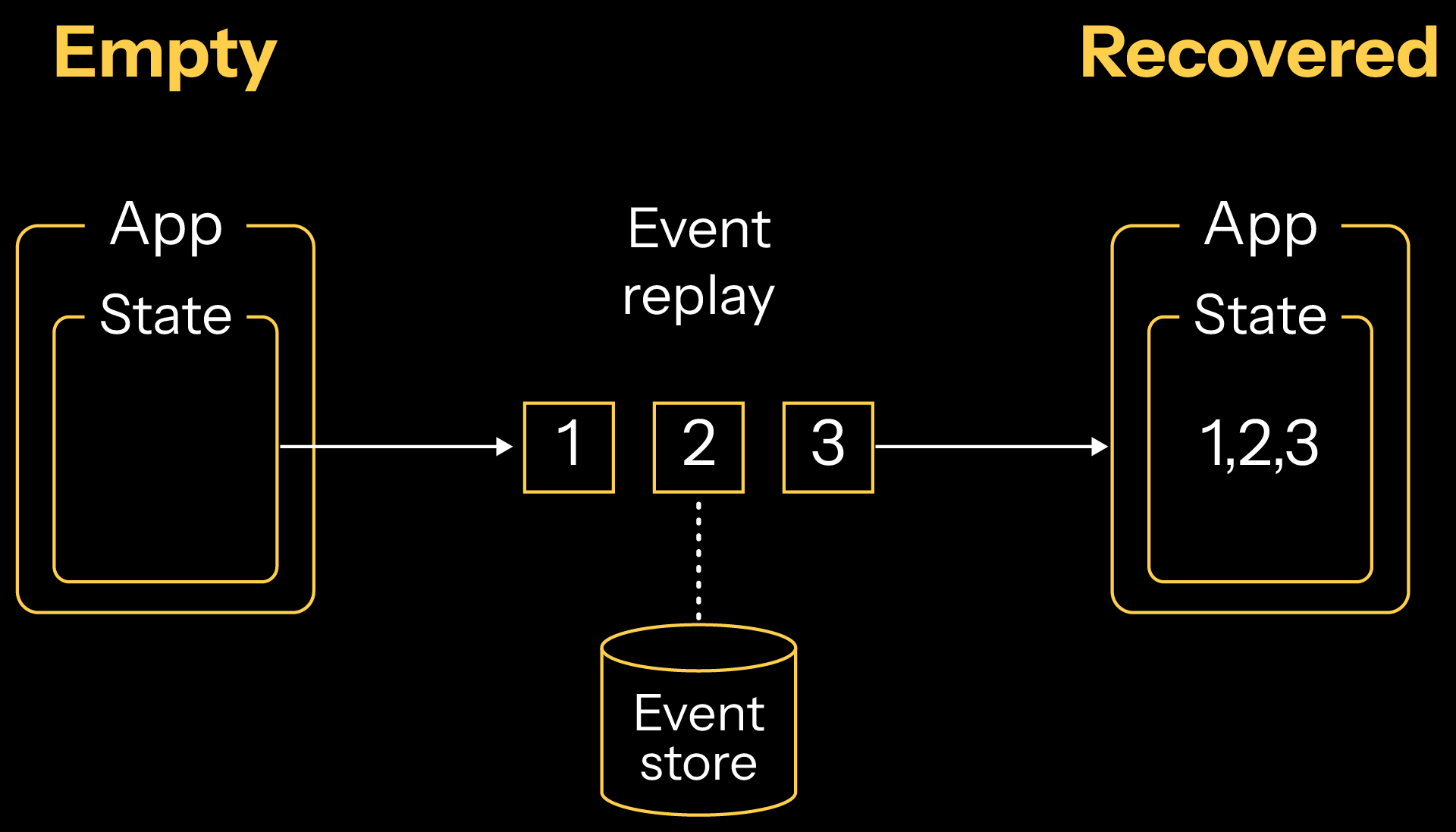
Events that track the state changes for your entities are automatically persisted into append-only data stores within the same region. In a failure scenario where all nodes for a cluster are destroyed, the entire application and all of its data instances can be recovered by loading and replaying events from the persistence store.
Fun fact: Akka not only shards the data within the memory of the nodes it runs in, but also can shard the persistence stores that data is stored into across (up to) 1,024 different data stores. By persisting sharded events across many stores, the overall system’s capacity and IOPS dramatically improves and this is an essential component to how we lower infrastructure fees (12 smaller databases are cheaper than 1 large one) while sustaining very high IOPS for a single application.
The event log is both persisted and networked. Events are advertised across the network and can be subscribed to by other services or brokers. Your application’s data events can be streamed for real-time consumption or piped into a messaging broker, like Kafka, for durable consumption by third parties.
Beyond dynamic scaling within a region, the Akka runtime is also responsible for managing the scheduling of your application instances, how data is sharded and rebalanced within the region, and end user traffic routing to the correct shard. It also streams events from your service instances to other services through service-to-service eventing.
Service-to-service eventing is a special type of brokerless messaging embedded within Akka. Much like the way that Akka is clustered from within, Akka applications are also messaged-from-within and can provide reliable, asynchronous, sequenced, and guaranteed delivery of messages from one application to another. For applications built with the Akka SDK, service-to-service eventing is automatic and can be used for applications sending messages between each other … or … replicating an application’s event log to another location – such as a region!
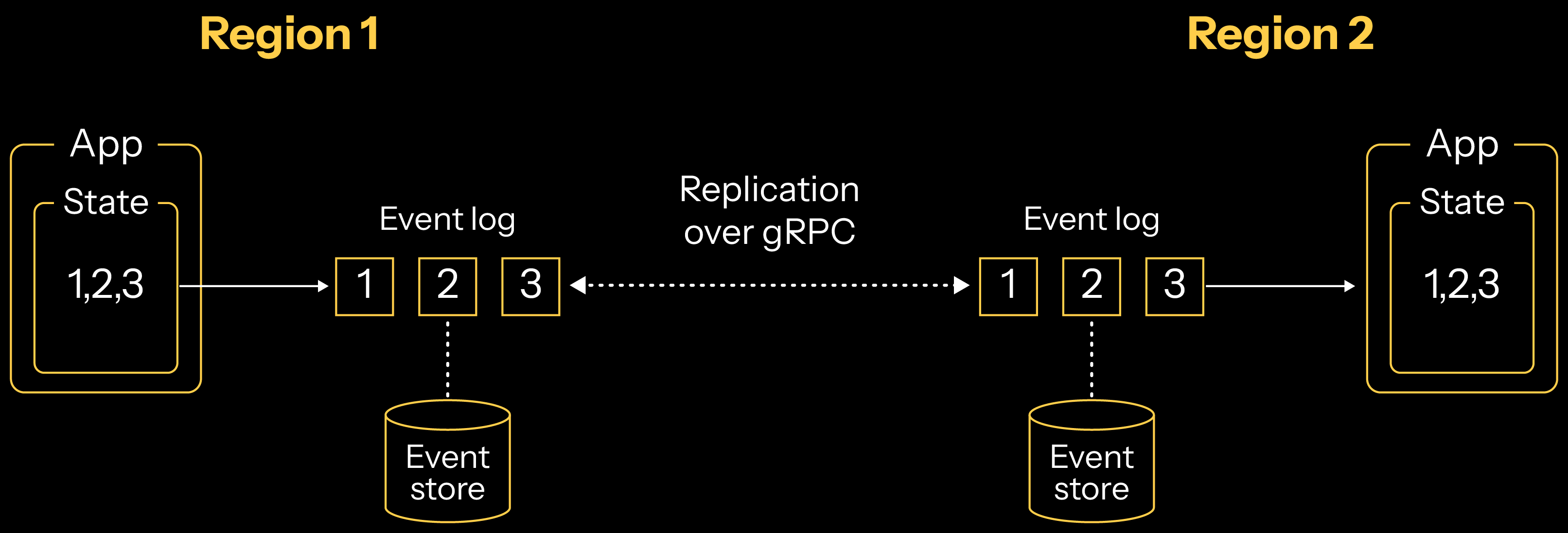
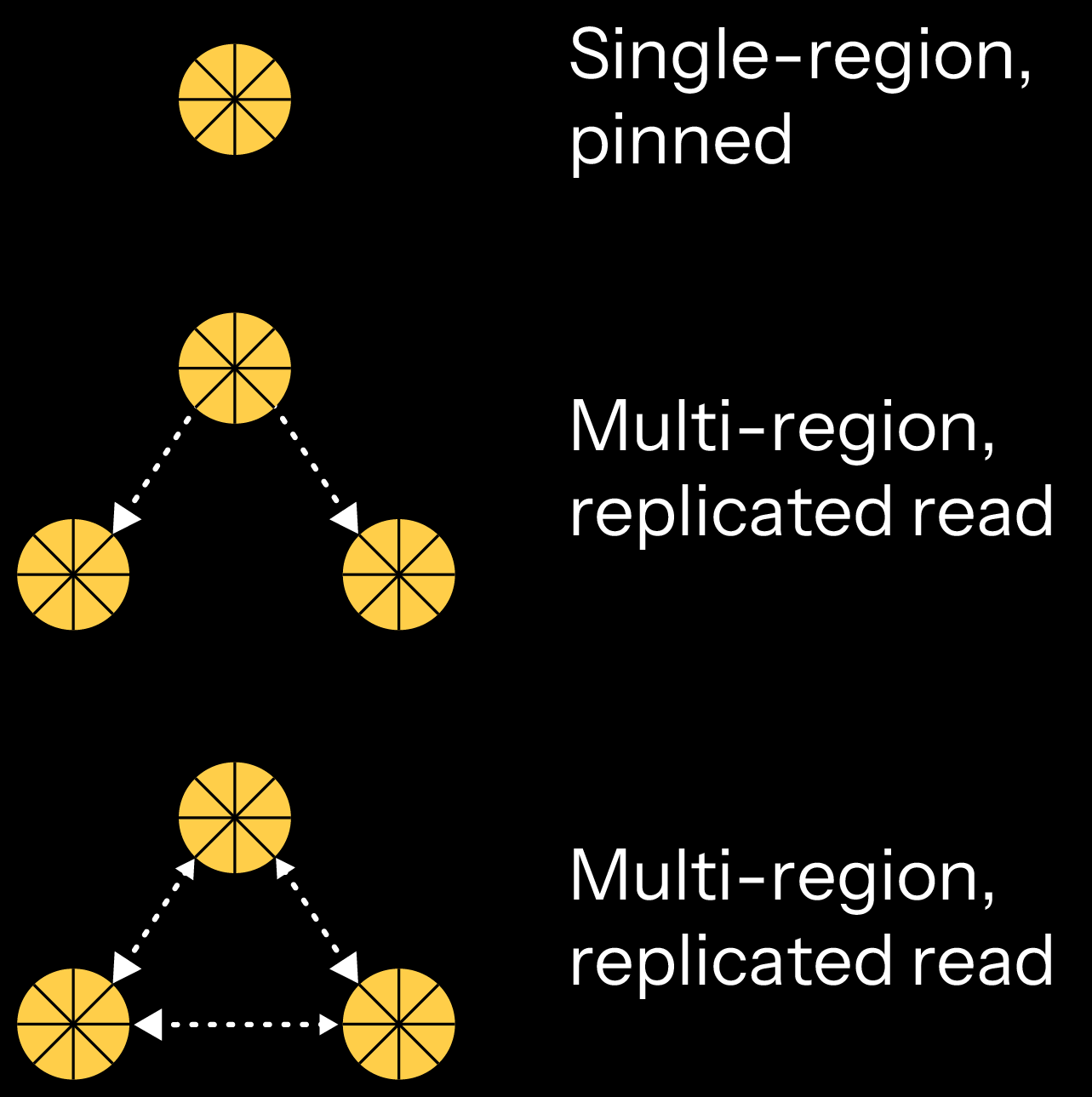
When your application is configured to replicate across different regions, each region receives a complete replication of the event log. Your application is running different Akka clusters within each region, and each cluster automatically persists the events that are received into their local persistence store. Users within a region are then able to read and write to the same data instance that was available in the originating region.
Routing
Akka offers two types of routing for read-replicated instances. In the static (default) configuration, you can designate a single region as the primary where all writable data instances reside and all other regions are merely holding read replicas. In the dynamic configuration, it’s expected that clients who will read data will likely be located in the same region that the data was created. With dynamic routing, the writable version of your data remains in the region it was created. This allows for each region to have some data that is writable, and then read replicas are sent to other regions. If a request from an end user to modify data is sent to the region that has a read-only copy, Akka handles the routing to forward the request to the region that holds the writable version of that data. In the replicated write scenario, each instance within each region is writable and additional routing is not required.
Federation
Federation is the coordination of multiple regions acting as a single substrate - discovery, registration, and connectivity that enables secure gRPC connections between multiple regions that your services treat as a single cloud.
Federation is possible regardless of where the region runs, whether it’s at Akka.io Serverless, a region you set up with BYOC, or a Self-Hosted region. Once regions have been federated, your projects can then individually map to one or more regions. Regions can be added or removed dynamically, and there are emergency modes where a rapid regional shutdown can occur. A regional shutdown requires that end user traffic to that region is terminated, all replication events are completed, and then an orderly wind down can be completed.
Deployment
Akka applications are built into microservices that are packaged in Docker images and hosted within a registry. Akka provides an embedded registry for each region, and you can optionally configure an external registry to host your images. Each region gets its own Akka image registry. At deployment, Akka coordinates the availability of your application’s image becoming available within the registry operating within each region.
Akka applications consist of one or more services, each of which is the individual packaging and deployment units. An application configured to use multiple regions is deployed separately and individually within each region, coordinated by Akka’s runtime. As applications are deployed within a single region, a cluster from within is created by the instances provisioned in containers running locally within that region. Each region then federates with the other regions to create the global control plane.
Akka applications get their own hostnames and service entries for each region they are deployed into. Operators configure routes that specify how the outside world is mapped to your Akka application. Routes handle local DNS configuration and publish the URL for external consumption.

Posts by this author
Share this article