


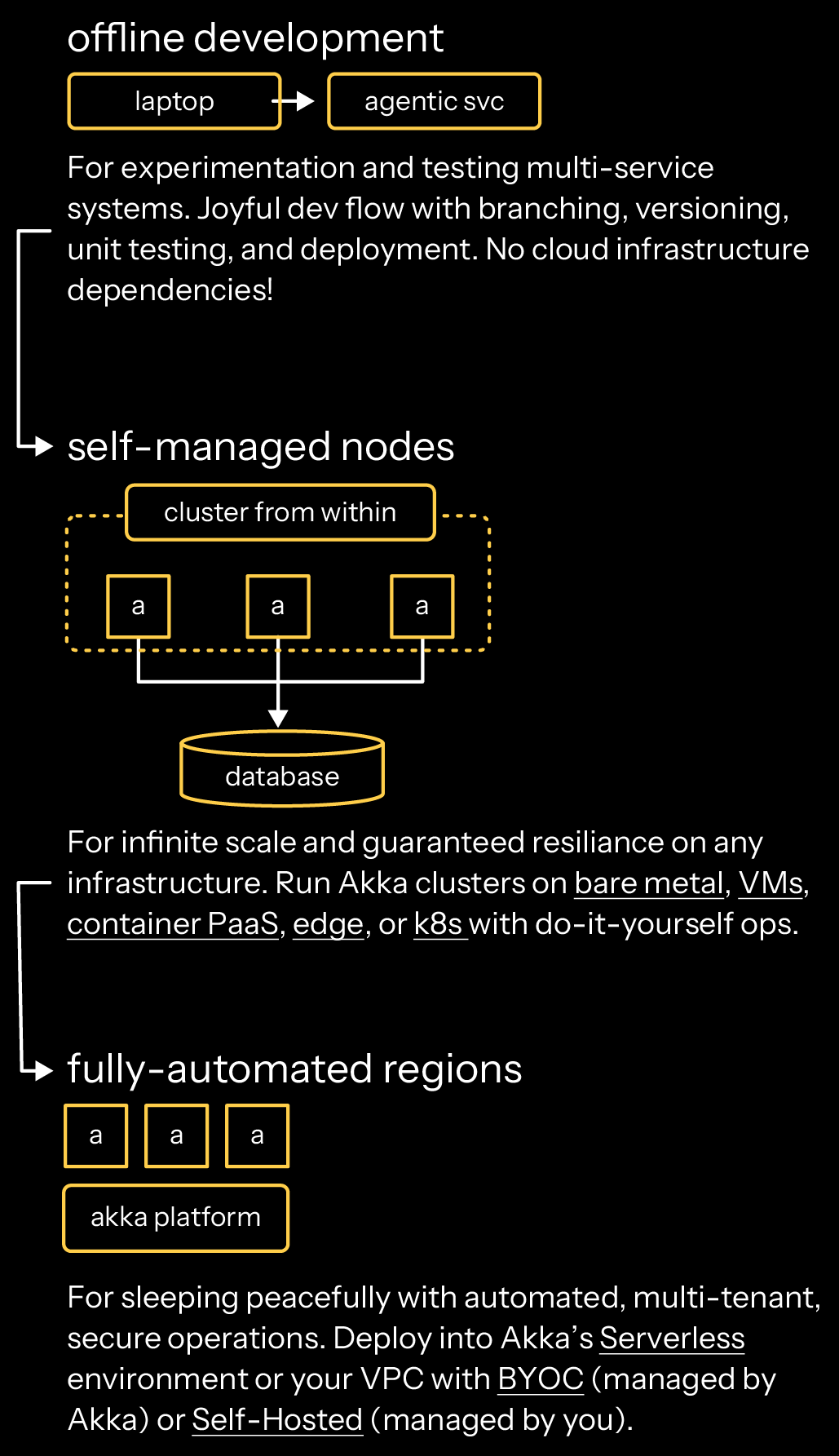
We are introducing new deployment options for services built with the Akka SDK: self-managed nodes and self-hosted Akka Platform regions.
In November 2024, we introduced the Akka SDK, which is the simplest and fastest way to build data, API, and agentic AI services with infinite scale and guaranteed resilience.
Services built with the Akka SDK were built offline (no cloud infrastructure dependencies!) and exclusively deployable into Akka Platform, hosted either at Akka Serverless or within your custodial VPC with Akka Bring Your Own Cloud (BYOC). Both deployment options are Akka managed services.
Today we announced two new deployment capabilities:
- Self-managed nodes. You can now run clusters of services that were built with Akka SDK on any cloud infrastructure.
The Akka SDK includes a self-managed build option that will create services that can be executed stand-alone. Your services are binaries packaged in Docker images that can be deployed in any container PaaS, bare metal hardware, VMs, edge nodes, or Kubernetes with any Akka infrastructure or Platform dependencies. Your nodes have Akka clustering built from within, which enables you to deploy fleets of services with infinite scale and guaranteed resilience. You take responsibility for the installation, upgrades, and maintenance of your services. Services built with the Akka SDK are licensed under BSL 1.1, and we provide a commercial license for usage in production.
To get started with this packaging, build services (using endpoints, workflows, timers, entities, streaming consumers, or views) with the Akka SDK and then select the stand-alone build option. - Self-hosted Akka Platform regions. You can now run your own Akka Platform region that does not require any dependency with Akka.io control planes.
Services built with the Akka SDK have always been deployable onto Akka Platform, with us providing managed services through our Akka Serverless and Akka BYOC offerings. Akka Platform provides fully automated operations, alleviating admins from more than 30 maintenance, security, and observability duties. Both Serverless and BYOC federated
multiple regions together by using an Akka control plane hosted at Akka.io.
Self-hosted regions are Akka Platform regions that have no Akka control plane dependency, which you install, maintain, and manage. Self-hosted regions can be installed in any datacenter with orchestration, proxy, and infrastructure dependencies specified by Akka. Since Akka Platform is updated many times each week, the installation of self-hosted regions is executed in cooperation with Akka’s SRE team to ensure stability and consistency of your environment.
No dead ends: From dev to multi-region replication without changing your code
Akka is the first dev framework that allows you to build a complete distributed system while offline and then package it for any deployment target you desire.
Whether you are debugging a multi-service system offline, deploying an Akka cluster into Heroku, or replicating your Akka data across multiple regions and clouds, your service is written once and ready for deployment everywhere.
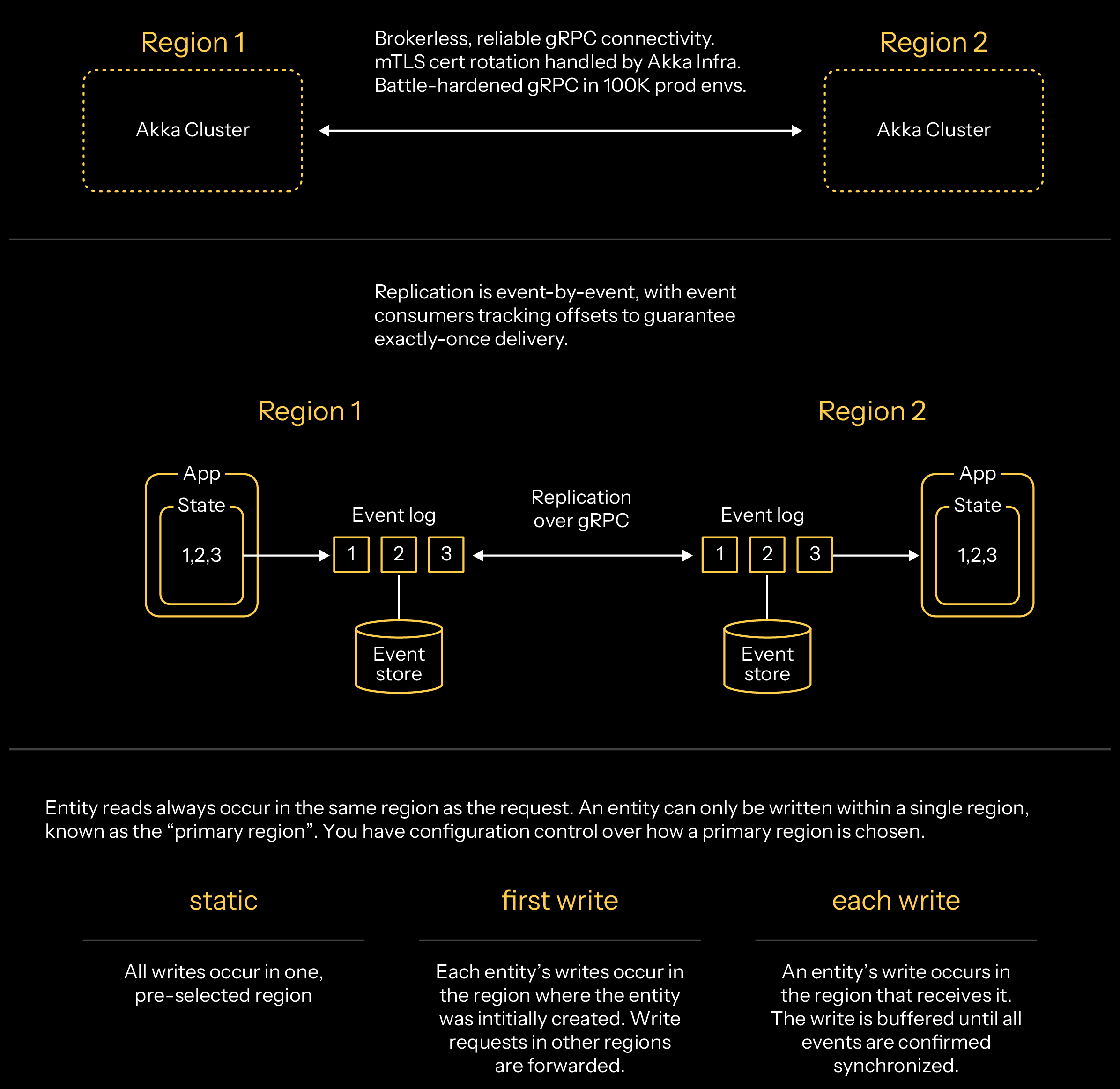
Now, with the latest releases of Akka, your apps have data replication across regions built in. Akka Platform discovers and federates multiple regions (running in different clouds if you desire) and enables your services to deploy into each region with full (or filtered) data replication in real-time. It’s this core capability that enables many customers to achieve 99.9999% availability.
Akka clustering - the magic behind elasticity and failover
Every other framework—whether the Spring Framework, Temporal, or Langchain—makes life challenging for teams transitioning from development to at-scale production. They each impose a combination of new packaging, APIs, libraries or frameworks that you must incorporate as you transition from their simple-to-start syntactic sugar into 24/7 operations environments.
There are many reasons that your services must be rewritten with other frameworks: integrations, enterprise security, underlying databases becoming a single point of failure, Python / TypeScript runtimes are not maintainable or scalable, and vendor commercialization that withholds production-quality readiness features accessible only to paying customers.
Another reason is that all these frameworks are not cluster-aware. Frameworks are typically optimized to help you build and run services locally, and that almost always means single-node operations. The services you build with “those other guys” are functionally capable, but the moment your service needs elasticity beyond a single node or multi-node failover, their paradigm breaks down, forcing your team into pain.
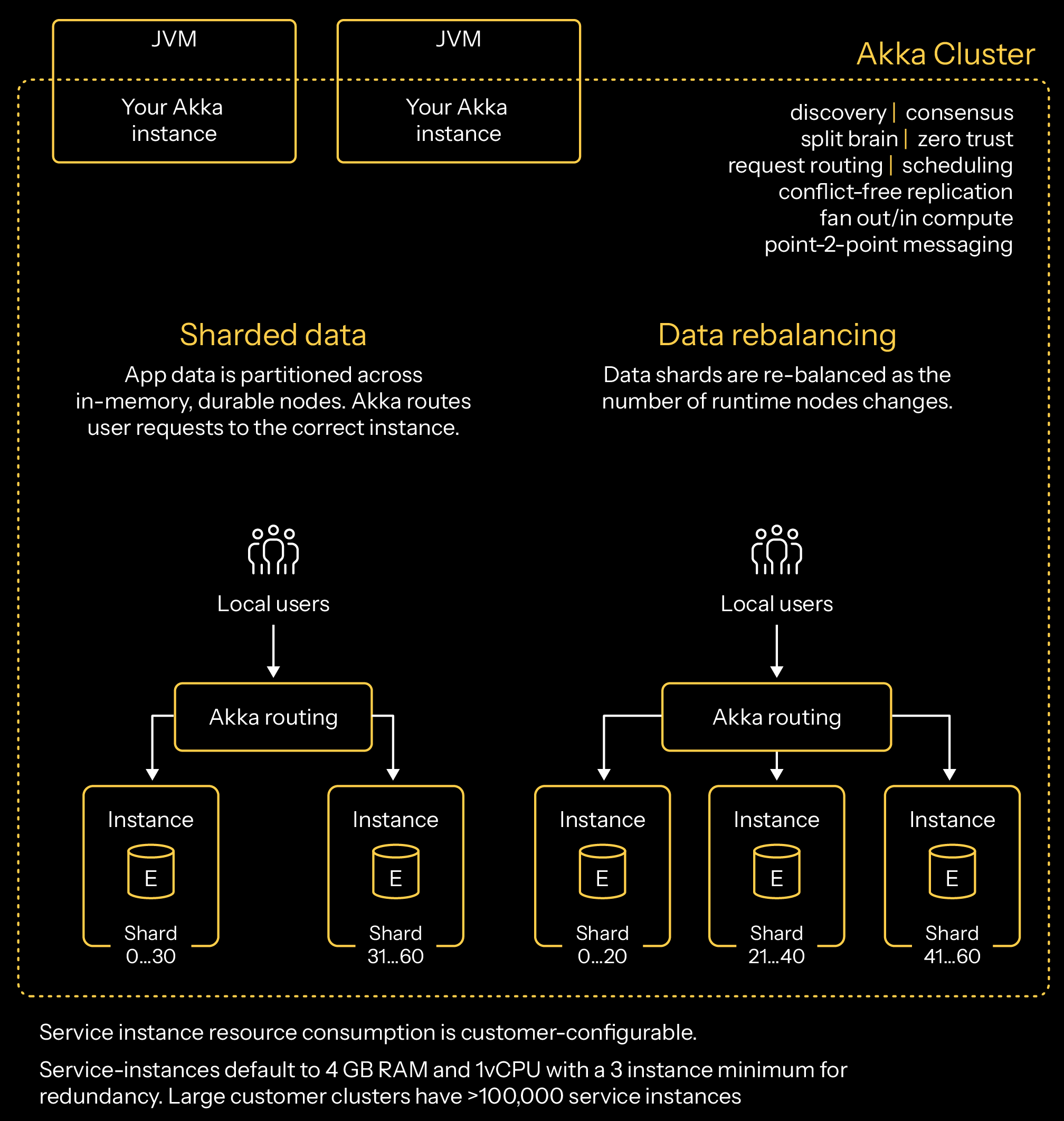
Akka first principles have always meant that your services are clustered. Unlike other frameworks, Akka services cluster-from-within, forming their own clusters through discovery and connecting with other Akka nodes. Whether you build an data, API, or agentic AI service, that service is inherently clustered. Moreover, whether your service is stateful or stateless, that service is inherently clustered. While you can opt to run a single node cluster of Akka, you can easily run a multi-node cluster.
Akka has been production-hardened over 15 years. Akka clustering doesn’t require you to install additional infrastructure or to install “a platform server” because the clustering is embedded within your services.
Single region runtime
Multi-region replication
Akka clustering is the magic behind how we achieve stunning benchmarks, ultra-low latency, real-time streaming with backpressure, and infinite elasticity.
Our team is very excited about this clustering 'magic', and today's announcement that gives you freedom to deploy the magic anywhere you want. Feel free to reach out to our team if you want to talk about what you're doing with agentic services...or any other tough systems engineering challenge. We've gotten pretty good at making the hard stuff simple.

Posts by this author
Share this article