
Blog
All the latest info and insights from the Akka team
Featured

CTO asks CTO: Jonas Bonér on Akka, AI agents, and distributed systems
Jonas Bonér joins Scalac’s CTO Asks CTO podcast to discuss Akka, AI agents, and the evolving challenges of distributed system design.
Design patterns for agentic AI
Learn how to build scalable, event-driven AI agents using agentic design patterns and platforms like Akka in this on-demand webinar.
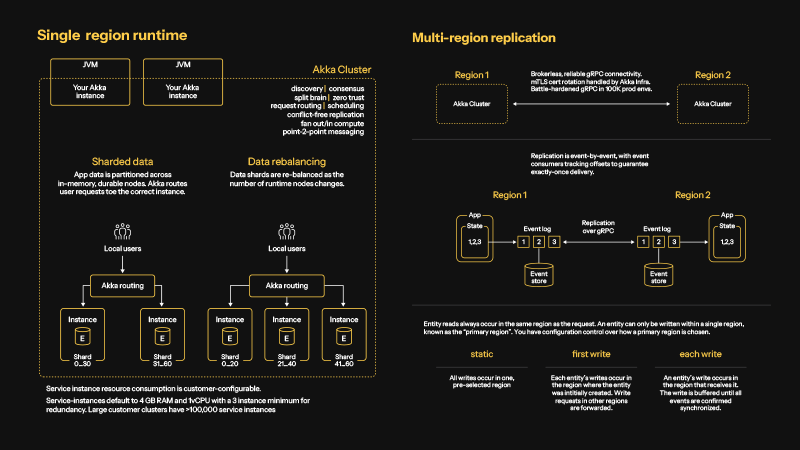
New Akka deployment options: elasticity on any infrastructure
We are introducing new deployment options for services built with the Akka SDK: self-managed nodes and self-hosted Akka Platform regions.
All Blogs

Jonas Bonér

Tyler Jewell

Team Akka


Duncan Devore
Tyler Jewell
Tyler Jewell

Kevin Hoffman
Tyler Jewell
Kevin Hoffman
Tyler Jewell
Tyler Jewell

Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Team Akka
Team Akka
Jonas Bonér
Tyler Jewell
Tyler Jewell
Andrzej Ludwikowski

Michael Nash
Jonas Bonér

Eduardo Pinto

Patrik Nordwall
Team Akka
Tyler Jewell

Christopher Hunt
Jonas Bonér

Jonas Bonér

Peter Vlugter
Patrik Nordwall
Patrik Nordwall

Johan Andrén
Jonas Bonér
Jonas Bonér

Janik Dotzel

Patrik Nordwall

Johan Andrén
Jonas Bonér
Patrik Nordwall
Michael Nash
Patrik Nordwall
Jonas Bonér
Jonas Bonér


