
Blog
Featured
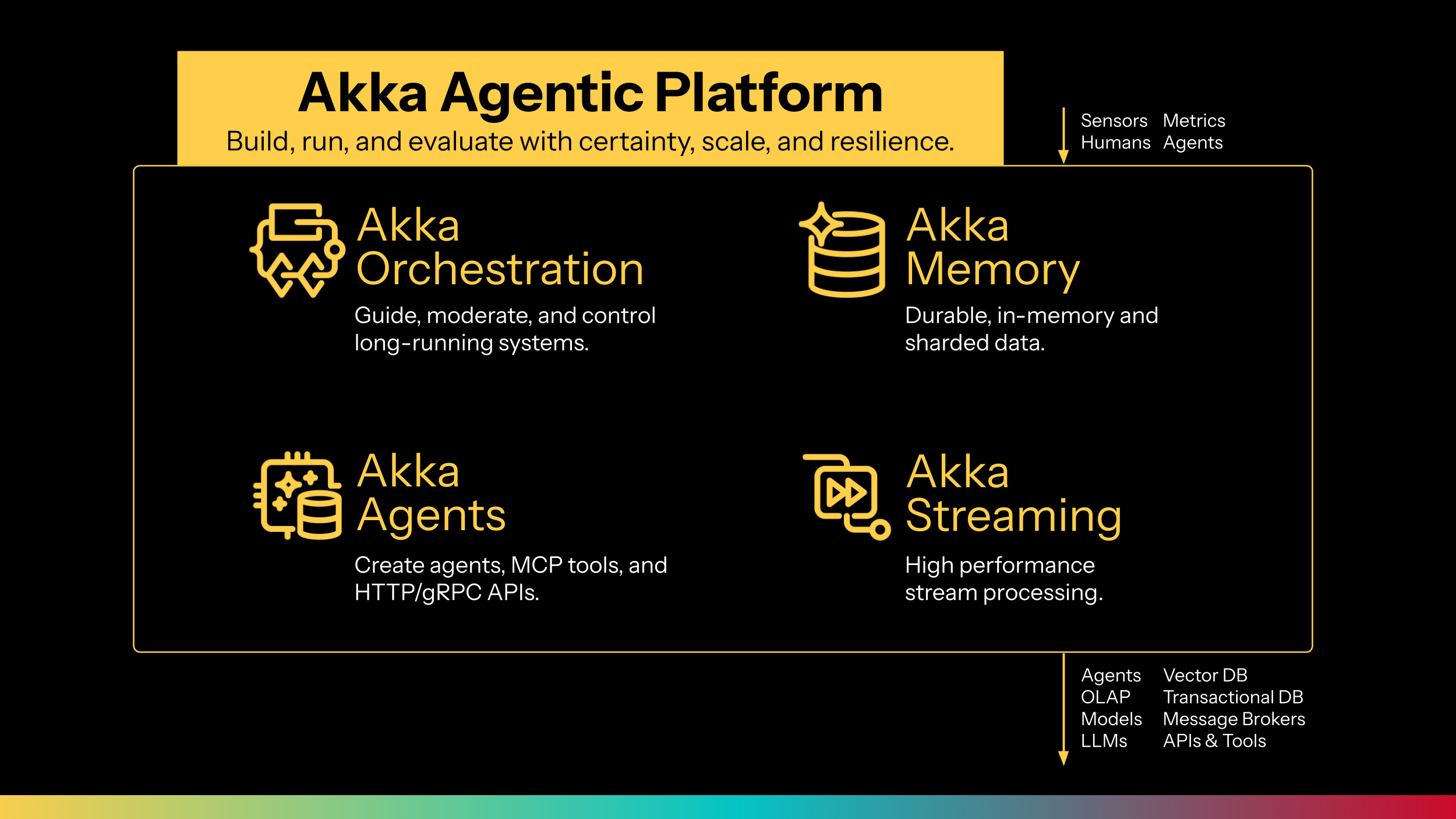
Announcing the Akka Agentic Platform

Introducing Akka’s new Agent component
Video: New Akka SDK Component: Agent
All Blogs

Tyler Jewell
Tyler Jewell
Tyler Jewell

Duncan Devore
Duncan Devore

Kevin Hoffman

Eduardo Pinto

Andrzej Ludwikowski

Johan Andrén
Duncan Devore
Duncan Devore

Jonas Bonér
Tyler Jewell

Team Akka

Duncan Devore
Tyler Jewell
Tyler Jewell
Kevin Hoffman
Tyler Jewell
Kevin Hoffman
Tyler Jewell
Tyler Jewell
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Andrzej Ludwikowski
Team Akka
Team Akka
Jonas Bonér
Tyler Jewell
Tyler Jewell
Andrzej Ludwikowski

Michael Nash
Jonas Bonér
Eduardo Pinto

Patrik Nordwall
Team Akka
Tyler Jewell

Christopher Hunt
Jonas Bonér

Jonas Bonér

Peter Vlugter
Patrik Nordwall
Patrik Nordwall
Johan Andrén
Jonas Bonér
Jonas Bonér

Janik Dotzel

Patrik Nordwall

Johan Andrén
Jonas Bonér
Patrik Nordwall
Michael Nash
Patrik Nordwall
Jonas Bonér
Jonas Bonér


