

Akka Streams provide a rich set of built-in combinators and utilities that users of the library can combine in flexible ways to achieve new functionality (most notable are the workhorses mapAsync and statefulMapConcat). With the GraphDSL and its first class cycles support one can build reusable pieces out of smaller building blocks, while still providing simple interfaces like a Sink or Flow (see https://doc.akka.io/docs/akka/2.4/scala/stream/stream-composition.html for more in-depth information). Still, there are times when these tools are not flexible enough and we need something more powerful. Akka Streams is based on, and fully compatible with, the interfaces standardized by the Reactive Streams specification (reactive-streams.org) so one might naturally think about implementing missing features directly in terms of the Reactive Streams APIs, Publisher, Subscriber and Processor. In practice this is much more work than one might expect. Reactive Streams are by far more than just 7 simple methods, they are a concurrency protocol that each of its parts must adhere to. These behaviours are tested by a rigorous and rather large set of tests in its official TCK (Technology Compatibility Kit) which we’ve built. As we were working on Akka Streams over the span of the last 2 years it became clear that customization cannot be ignored and the Reactive Streams interfaces are too low level for general purpose stream programming, and especially end-users should not be exposed to the pains of implementing a correct Processor if they wanted to extend Akka Streams with new functionality. Hence, the GraphStage API was born.
This is an introductory post where I will enumerate and introduce the features that the GraphStage model provides. Don’t worry if you don’t fully understand all the details here, we will explain these in detail in future posts.
Backpressure model
Backpressure, in general, is a method where a consumer is able to regulate the rate of incoming data from a corresponding producer. One possible way to implement backpressure is to have the consumer handing out permits to the producer: “you are allowed to send 4 more items”. If a producer runs out of permits, it must stop until further permits arrive. This is exactly the same method that Reactive Streams specifies (you might want to read this interview with the creators for more details: Viktor Klang’s Reactive Streams 1.0.0 interview).
When we talk about backpressure, we usually assume that the two entities, the producer and consumer can progress independently, concurrently, otherwise there is not much need to regulate rates since they execute in lock-step, synchronously. Right? Almost. It is quite possible that a long chain of single-threaded computations is sandwiched between a concurrent producer and consumer:
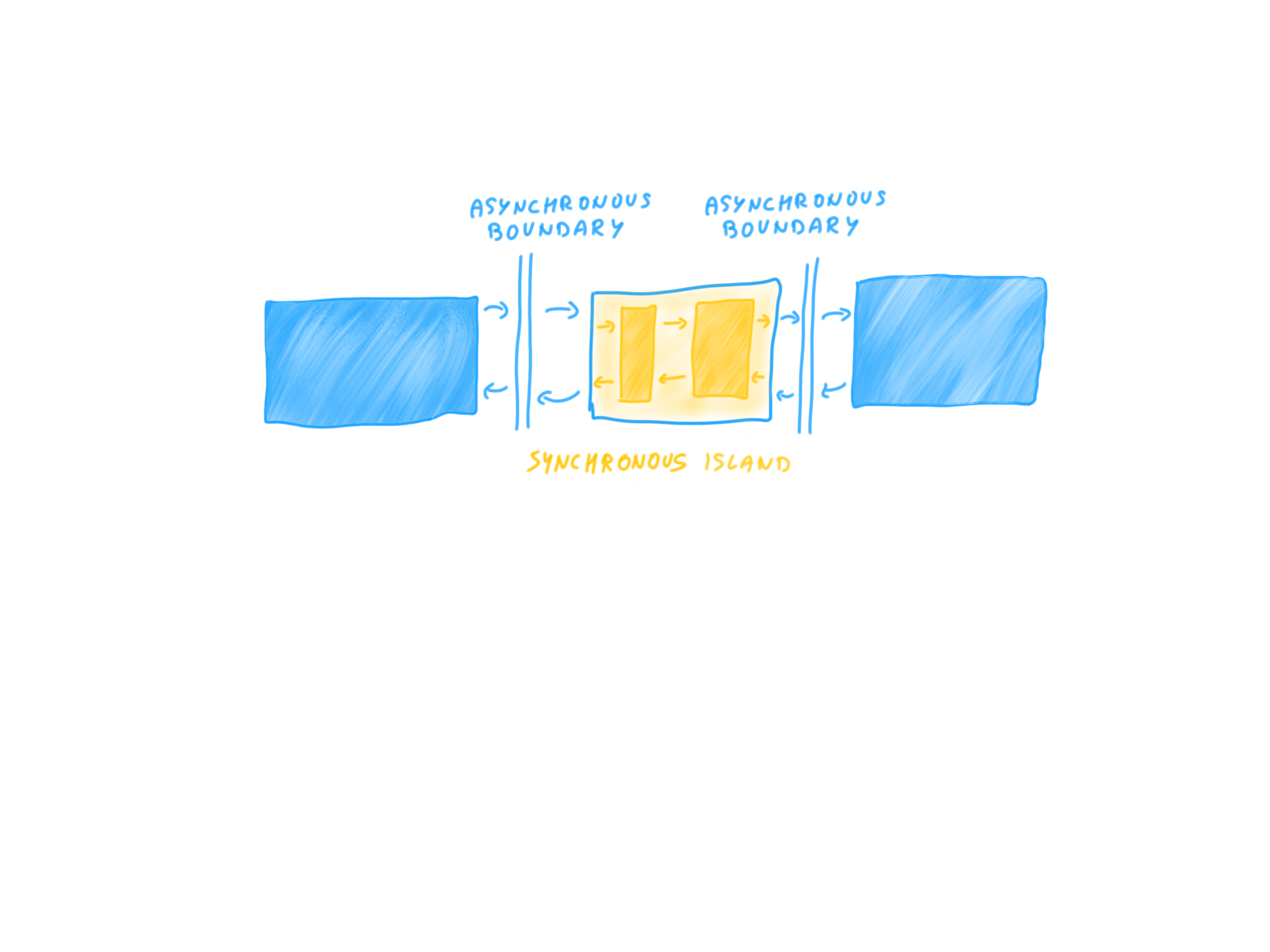
Although the stages of the pipeline in-between execute synchronously, in lock-step, they must still preserve backpressure across all steps of the chain. One example would be a stage in the pipeline that is a 1-to-N stage, emitting multiple elements for each consumed element. In this case, even though the downstream consumer can accept, let’s say 100 elements per second, and the upstream producer does not provide more than 50 elements per second, putting a 1-to-100 stage in-between will still result in overwhelming the consumer fiftyfold. Take for example an upstream producer of user identifiers: its output processed by a stage that emits the last 100 activities for that user id will amplify the rate of user ids hundredfold. It is clear that the stage itself must properly translate the backpressure signal between its upstream and downstream. If there are several such stages in a synchronous chain, then the translation must happen at each of them even though they are running synchronously. Somewhat more complicated is the situation when N-to-1 stages are added to the chain (think of a simple .filter()). As a consequence, we wanted to have an abstraction that preserves and properly translates backpressure in synchronous and asynchronous settings as we expected a mixture of these to be used in practice.
There is one important simplification that we figured out early when we experimented with various models for custom stages that can work in both synchronous and asynchronous settings (and the most ambitious: for arbitrary graphs). It is not necessary to use a variable count of permits in the synchronous setting, it is enough to have at most a permit of 1 between each consumer/producer. This simplifies the model of communication to two simple operations (not counting closing)
-
Pull - a consumer can
pullits input to request a new element. It cannot be pulled again until a new element arrives -
Push - a producer can
pushto its output if it has been pulled before. It cannot push again until a new pull arrives
(these states, and the full state-space of input and output ports are fully described in the documentation: Port states: InHandler and OutHandler)
This is a very simple model, but one might wonder, how does this map to the more generic permit based model of Reactive Streams? It would be very inefficient if Akka Streams based Subscribers would request from a Publisher one-by-one, instead of requesting larger batches, since in an asynchronous setting all communication have a cost. The solution is that in Akka Streams, a stage that has an asynchronous upstream pulls from a buffer, not directly from the upstream Publisher, and it is the buffer that requests new elements once a certain number of elements have been taken out (usually half the buffer size).
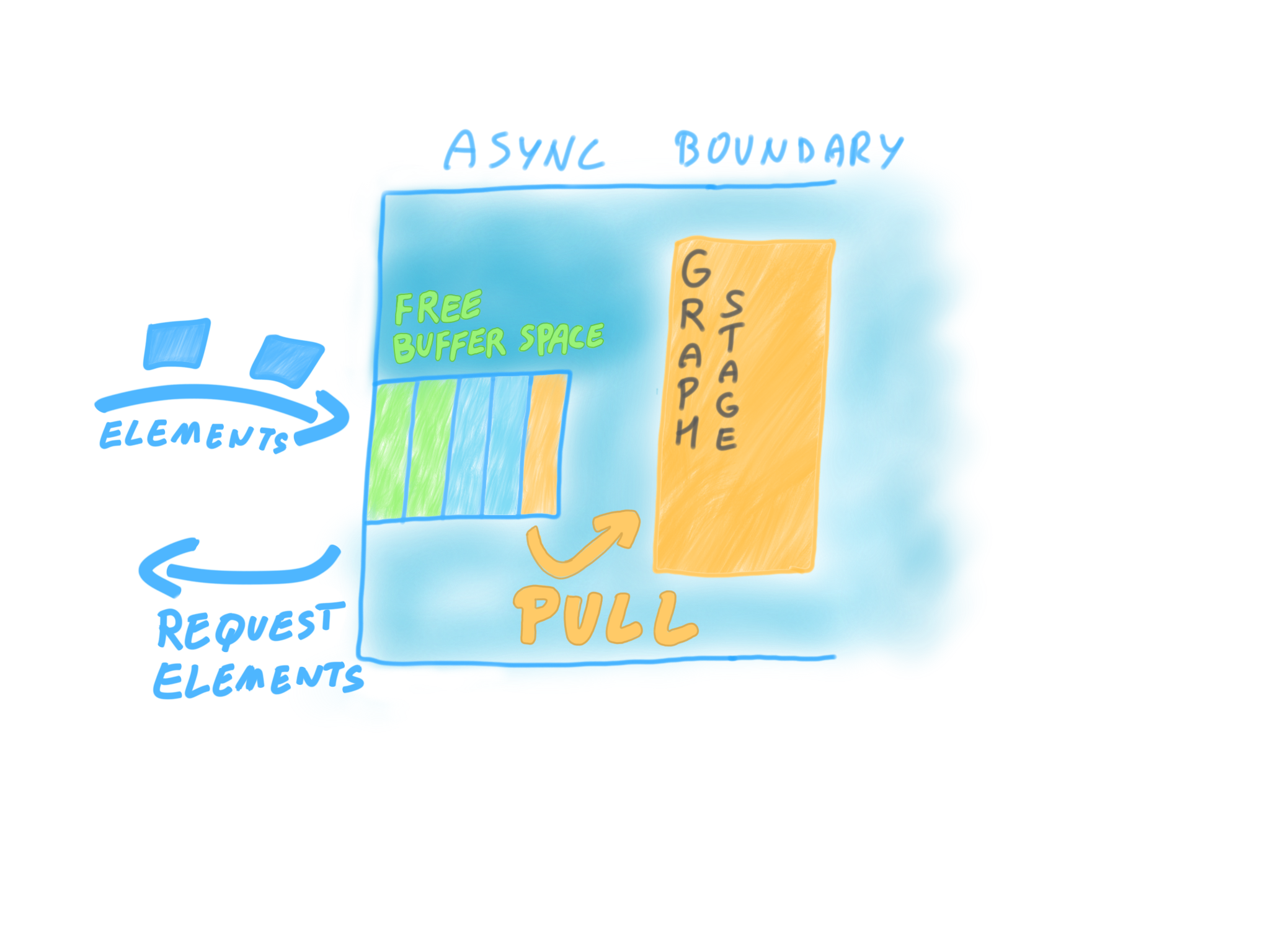
In summary, the GraphStage API provides a simplified model of Reactive Streams backpressure and a model that works seamlessly in asynchronous and synchronous settings (and the mixture of these), handling all the buffering automatically for you. On top of this, we also hide all the nitty-gritty details of the Reactive Streams specifications from you: it is not necessary to test your stages against the TCK as they are already conforming by design.
Solving TCK compliance is just one of the issues though. In practice, it is the concurrency part where things tend to blow up in rather spectacular ways.
What’s more, with low-level implementations such errors would happen “sometimes”, making them insanely hard to reproduce and debug; with GraphStage you get all the information about the mistake at the first mistake.
Threading model
In the GraphStage API, all the callbacks you might receive are linearized.
This means that you can safely assume that no two callbacks will execute at the same time (or overlap). Or to put it another way, callbacks are not concurrent with each other. There is also no need to worry about visibility of local variables of a stage: it is properly handled by the library for you. The whole model is very similar to how actors work, where messages are processed in sequence, and accessing local state while handling the message is safe. No need to mess around with volatile variables, atomics or locks to safely manage internal state. Again, I have to emphasize, this is fully transparent and your stage will work in both asynchronous and synchronous settings. Even better, the internal implementation does not use any locks either, and is non-blocking in general.
Error handling model
It is great to have all these features that reduce exposure to concurrency issues, but there are still plenty of mistakes to make, and bugs to write. I have good news for you. The GraphStages API provides excellent error handling (I am allowed to say “excellent” here as I have debugged so many streams issues that I have earned this right with tears and blood ;-)). There is no need to put try-catch blocks around your code just to prevent the error to propagate to an unknown place (the thread-pool thread that you are running on for example) and to turn it into a proper Reactive Streams teardown event, onError. Catch the errors that you can handle, and leave the rest to Akka Streams. Your error will be properly caught and translated to the necessary stream signals, your postStop will be called, and the stage will retire in peace properly closing every input or output port that was still open.
What about bugs related to streams itself, like trying to overflow a downstream consumer? Unlike in raw Reactive Streams land, where such an act is undefined behavior, the GraphStage infrastructure (the mighty GraphInterpreter to be precise) intercepts the attempt and will
-
Log the error telling you what you did wrong (
"Cannot push port P twice") -
Throw an exception
-
The exception is turned into stage completion, properly signalling the error to all Subscribers and closing all ports
In other words, even mistakes like this are turned into a clean shutdown with detailed information on the cause. If you would write a raw Reactive Streams Publisher there would be no guarantee on what happens as the Subscriber getting the overflow might or might not throw an exception. Even if it would, you would need to protect all those calls with a try-catch and put cleanup logic to all those places (with even more edge-cases, like “am I allowed to signal the error to the Subscriber which I just messed up right now by overflowing its buffer?”). What’s worse with low-level implementations is that often such errors would happen “sometimes”, making them insanely hard to reproduce and debug; with GraphStage you get all the information about the mistake at the first mistake.
We had various issues related to trying to request more elements than we can handle, or emitting more elements that was requested, or trying to access already closed inputs or outputs. We implemented these safety features to fix these problems once and for all. Thankfully, these are available to you, too.
Lifecycle model
On top of the robust error handling model sits the equally useful lifecycle model that simplifies resource management and safe retirement of stages when they stop (failing or normally). The two entry points, preStart and postStop are invoked at the start and the end of the life of a stage. It is very common to put cleanup logic in postStop as it is guaranteed to be called just before the stage goes away. If you happen to throw an exception in postStop, it will be handled, preventing it to do harm to anybody else. If you use IO or other external resources, this is a life-saver.
It is a quite common mistake, especially in more complex graph processing settings with multiple ports to forget to stop the underlying machinery (an actor, thread, or just cleaning up internal state). GraphStages by default automatically stop once all of their input and output ports have been closed (internally or externally). This prevents this common mistake, and also makes it possible to write certain stages in a very elegant way, delegating completion to this built-in mechanism. If you need to keep the stage alive for some reason (for example because it needs to do some extra rounds of communication with a 3rd party library to close it gracefully) it is possible to do so, too.
Apart from usual stream termination cases caused by completion or in-stream failures, we also handle when the ActorSystem or Materializer backing the running stream is stopped. You can simply pull the plug on an ActorSystem by calling terminate() and all stream stages will attempt to properly stop themselves, calling postStop() along the way before the system fully stops. This is among the reasons why postStop() is such a valuable tool for resource cleanup.
Out-of-the-box graph support
What if you need something more complex, something with multiple inputs and outputs? You already have what you need. When it comes to GraphStages there is no special casing for any of the common cases like Sink, Source or Flow. If you have implemented any of these, your knowledge immediately transfers to the more general graph cases (BidiFlow, fan-in and fan-out stages, or arbitrary other shapes). While this approach means that you need to write a little bit more boilerplate in the simple cases like writing a Sink, once you learn the basics you don’t need to learn a different API for the generic cases.
Support for asynchronous side-channels
In many cases, might need to receive events from the external world in a non-streaming way while interacting with streams. Timers are one example, but we might be also interested in a completion of a Future, or we might want to receive messages from an actor. This is all possible with GraphStages, without forfeiting any of the nice safety features! External events are handled in your stage via callback you provide. These still maintain the sequential ordering guarantee just like any of the stream related callbacks. You can still safely access the state of your stage. And of course, error handling works as usual.
These features will all be detailed in future posts of this series, for now, you can look at the documentation for more detailed explanation: (Using timers, Using asynchronous side-channels)
Is there anything else?
Yes there is ;-) Let’s not go that deep in this post, it is rather lengthy already. I hope I managed to demonstrate the underlying complexity (and the abyss) of writing correct stream processing stages. There are edge cases, undefined behavior, resource leaks lurking around every corner when you go down to raw Reactive Streams interfaces. We have been there, and we wanted to solve the problems we encountered once and for all, and provide an abstraction that we use internally and something that we can rely on. Today, practically all of our built-in operators are implemented as GraphStages.
We believe that if you ever need to build custom processing stages not expressible in terms of built-in combinators, a GraphStage is a good choice as it provides an excellent safety net built on more than 2 years of suffering debugging experience.