

Apache Kafka is the leading distributed messaging system, and Reactive Streams is an emerging standard for asynchronous stream processing. It seems natural to combine these two; that’s why SoftwareMill started the reactive-kafka project back in December 2014 and maintained it since.
Recently we’ve combined efforts with the Akka team, and now the project can leverage the expert input from the Lightbend Akka maintainers themselves (Patrik Nordwall and Endre Varga), community (Alexey Romanchuk) and the original reactive-kafka authors (Krzysiek Ciesielski from SoftwareMill).
As a result of this collaboration, we’re pleased to announce the 0.11 release of the project, which brings a lot of updates! Integrating Kafka into your reactive data processing pipeline is now even easier than before.
First of all, we have a redesigned API, which should be in-line with other reactive-* connectors (see also the Alpakka initiative), as well as provide additional flexibility. As an example of a common task, to read data from a Kafka topic, process it and commit offsets in batches collected within 10 seconds or at most 30 messages, you can define your stream as follows:
val consumerSettings = ConsumerSettings(system,
new ByteArrayDeserializer, new StringDeserializer)
.withBootstrapServers("localhost:9092")
.withGroupId("group1")
.withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val result = Consumer
.committableSource(consumerSettings, Subscriptions.topics("topic1"))
.mapAsync(3)(processMsg)
.groupedWithin(30, 10.seconds) // commit every 10 seconds or 30 msgs
.map(group => group.foldLeft(CommittableOffsetBatch.empty) {
(batch, elem) => batch.updated(elem) })
.mapAsync(3)(_.commitScaladsl())
.runWith(Sink.ignore)
result.onFailure {
case e: Throwable => handleError(e)
}
More examples in Java and Scala, with explanations, can be found in the documentation.
Secondly, there are significant performance improvements. We’ve done some benchmarks, and while there is still some overhead from the reactive-kafka wrapper (though keep in mind, that you also get something in return: e.g. all of the benefits coming from a nice API with asynchronous backpressure!), the overall numbers look very good and are getting better.
Here’s a couple of common Kafka usage scenarios, comparing the old reactive-kafka version (M4), the current version (0.11), and equivalent functionality implemented using plain Kafka Producers/Consumers (but not taking into account, of course, connecting with any other reactive components).
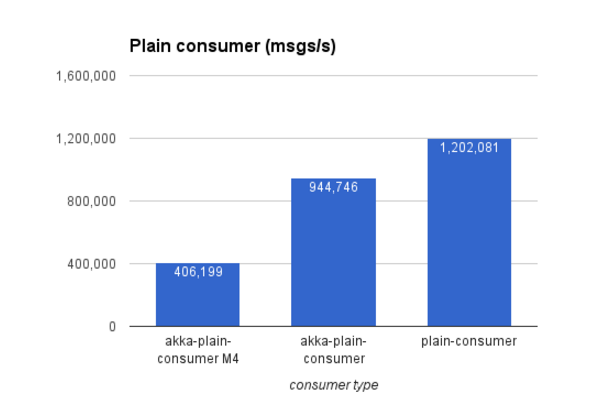
The first scenario represents a consumer which reads messages from Kafka and pushes it through a non-blocking processing stage, without commit. The reactive setup (akka-plain-consumer) gets very close (80%) to full speed achieved with a while loop pulling elements from a consumer (plain-consumer).
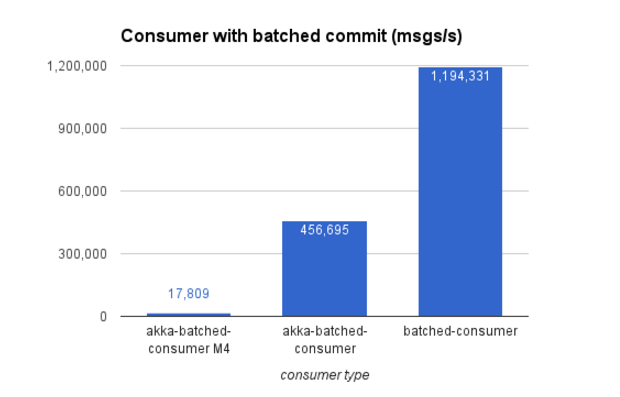
Another scenario represents a very common use case - consuming messages and committing in batches in order to achieve at-least once delivery. Performance improvements in 0.11 allowed to gain a massive throughput increase from ~17k to ~450k msgs/s.
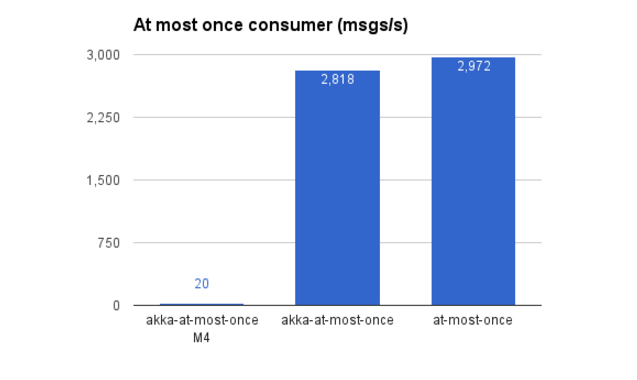
Sometimes one needs to commit each single message before processing, which gives at most once delivery guarantee. 0.11 optimizations fixed the super-slow value of 20 msgs/s in the previous implementation, and reached over 2800 msgs/s. This is a great step forward, very close to the simple while loop scenario (“at-most-once”).
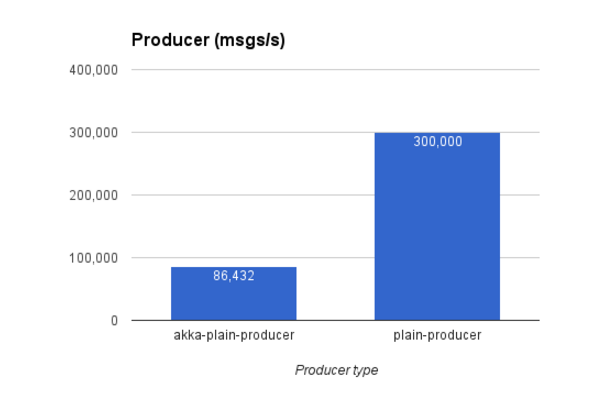
Our last benchmark tests a producer continuously sending messages to a Kafka topic. Current version of akka-stream-kafka writes over 85,000 messages per second. This result has been achieved with producer parallelism set to 100, which indicates how many parallel writes can be waiting for confirmation until this stage backpressures. The “plain-producer” test chosen for comparison writes to Kafka in a loop being bound only by its internal buffer size.
Give it a try, we’d love to hear your feedback!
This post is part of the "Integration" series. Explore other posts in this series:
- Akka Streams Integration, codename Alpakka
- A gentle introduction to building Sinks and Sources using GraphStage APIs (Mastering GraphStages, Part II)
- Writing Akka Streams Connectors for existing APIs
- Flow control at the boundary of Akka Streams and a data provider
- → Akka Streams Kafka 0.11
- Custom Flows: Parsing XML (part I)
- Custom Flows: Parsing XML (part II)